Deep Saliency Prior for Reducing Visual Distraction
CVPR 2022
Supplementary Material
- Supplementary PDF - with more details on the method, the user studies we conducted, and additional baselines.
- 1. Example result on a video conference call (Figure 8)
- 2. Results - reducing saliency (Figure 1, Figure 6)
- 3. Results - increasing saliency (Figure 7)
- 4. Eye-gaze study results (figure 9)
- 5. Comparison with attention retargeting approaches; (figure 10)
- 6. Comparison with "Look Here!" (figure 11)
- 7. Results driven by another saliency model
- 8. Results generated by automatically extracted masks
- Gaze Study
Saliency Driven Warping - Visualization
Here we visualize the intermediate steps of the warp operator optimization (supplementing Figure 4):
| Input | Optimization (Zoom-in) | Optimization (Zoom-in) | Output | |||
 |
 |
 |
 |
1. Example result on a video conference call
We apply our approach to a video conference call, aiming at reducing background clutter while maintaining the overall appearance of the room or the office. We segment the regions where the predicted saliency is above a threshold (0.15). For each distracting region, we apply our different operators and select the one that yields the lowest saliency value within the region, then apply the per-distractor parameters to the corresponding regions in all the frames (processing the video frame by frame independetly).
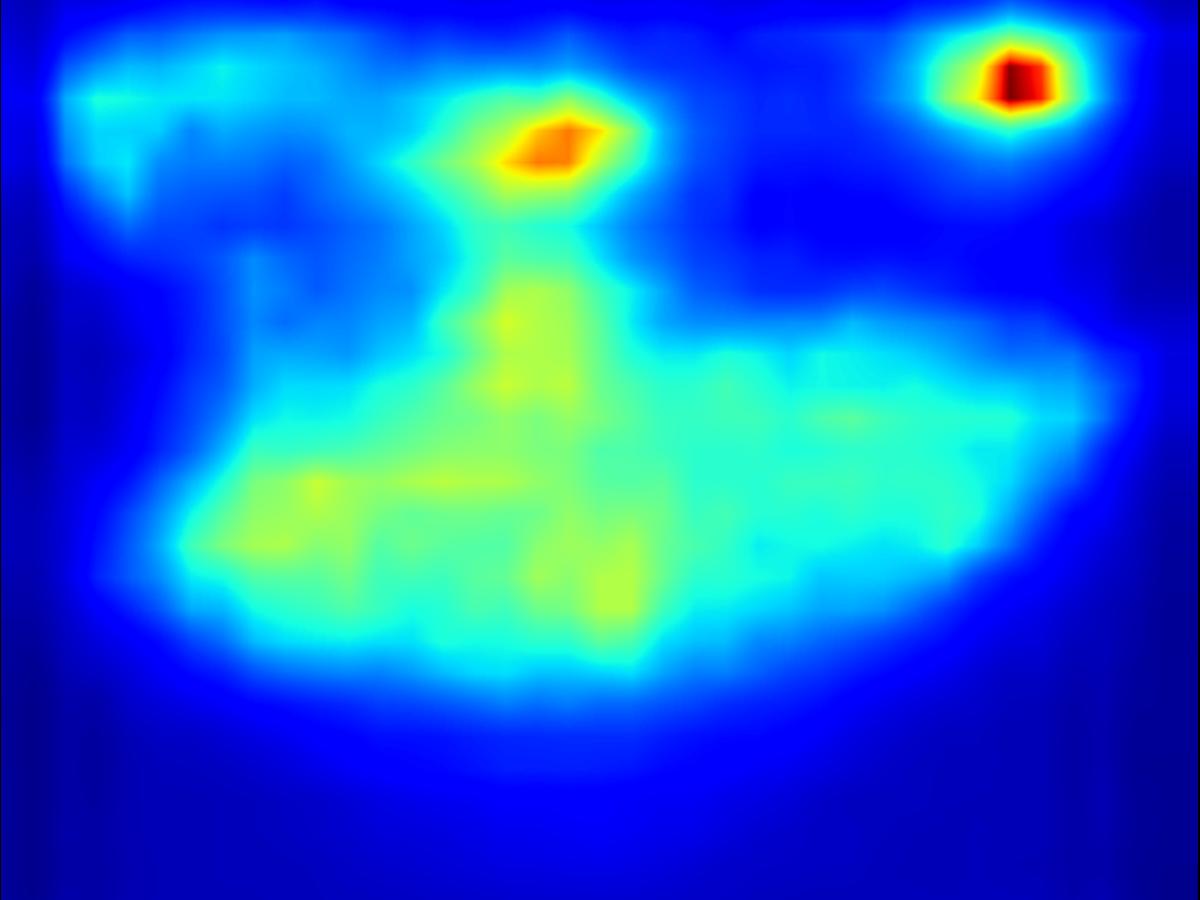
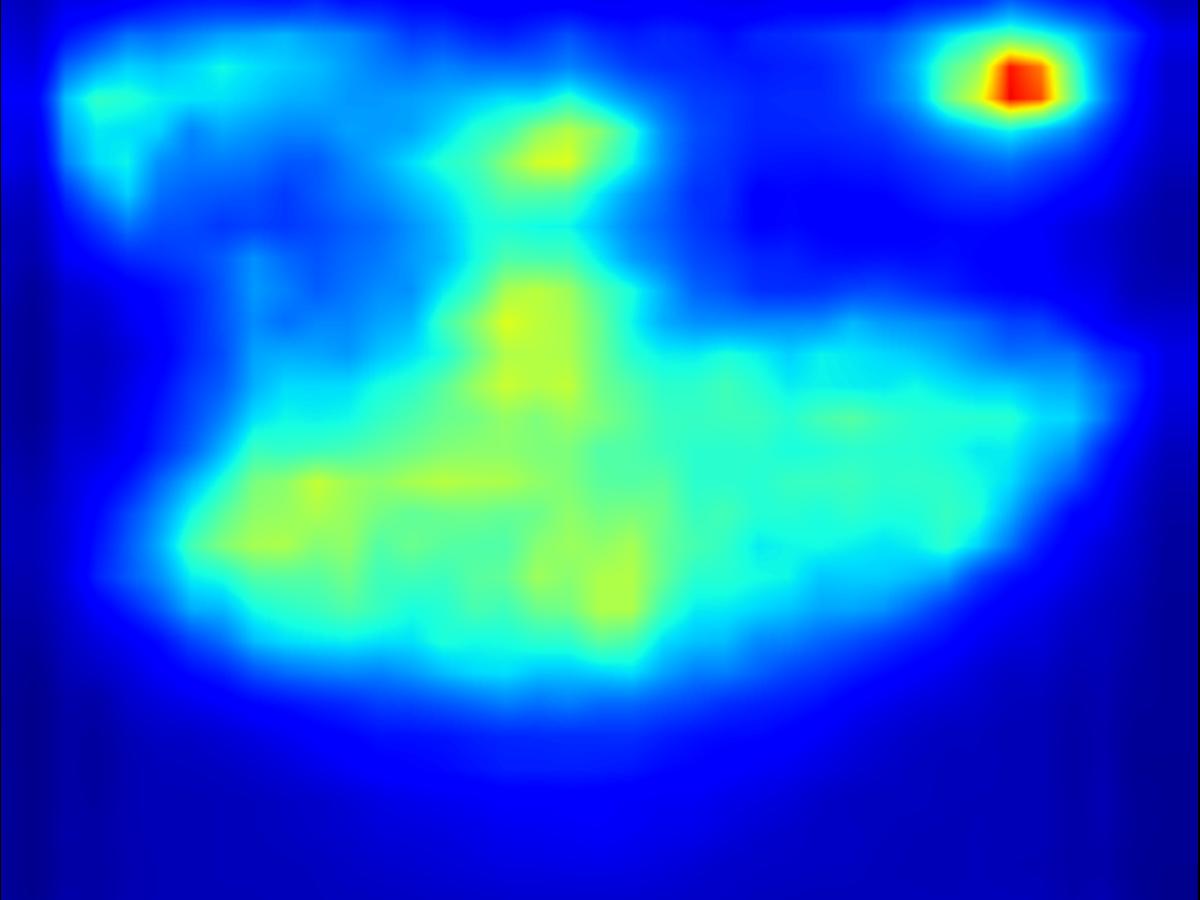
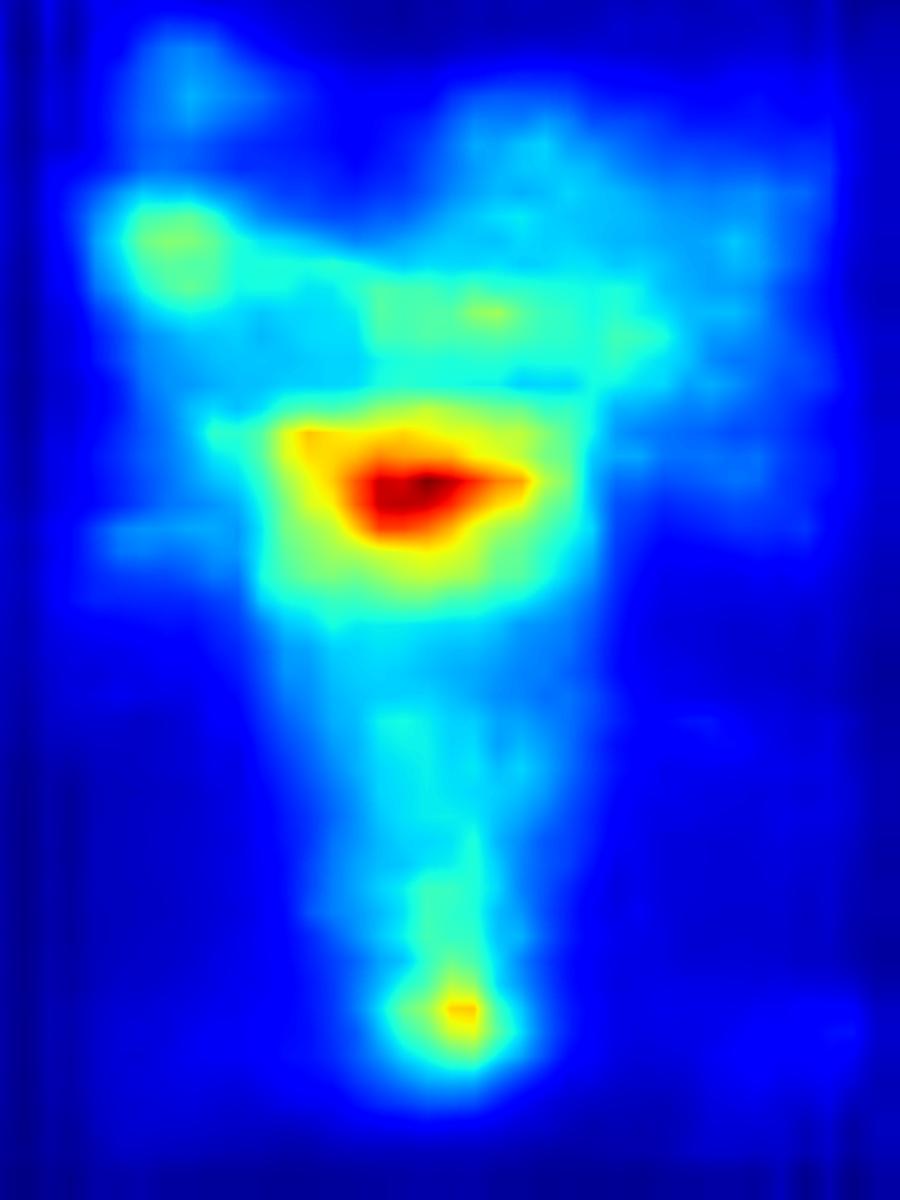
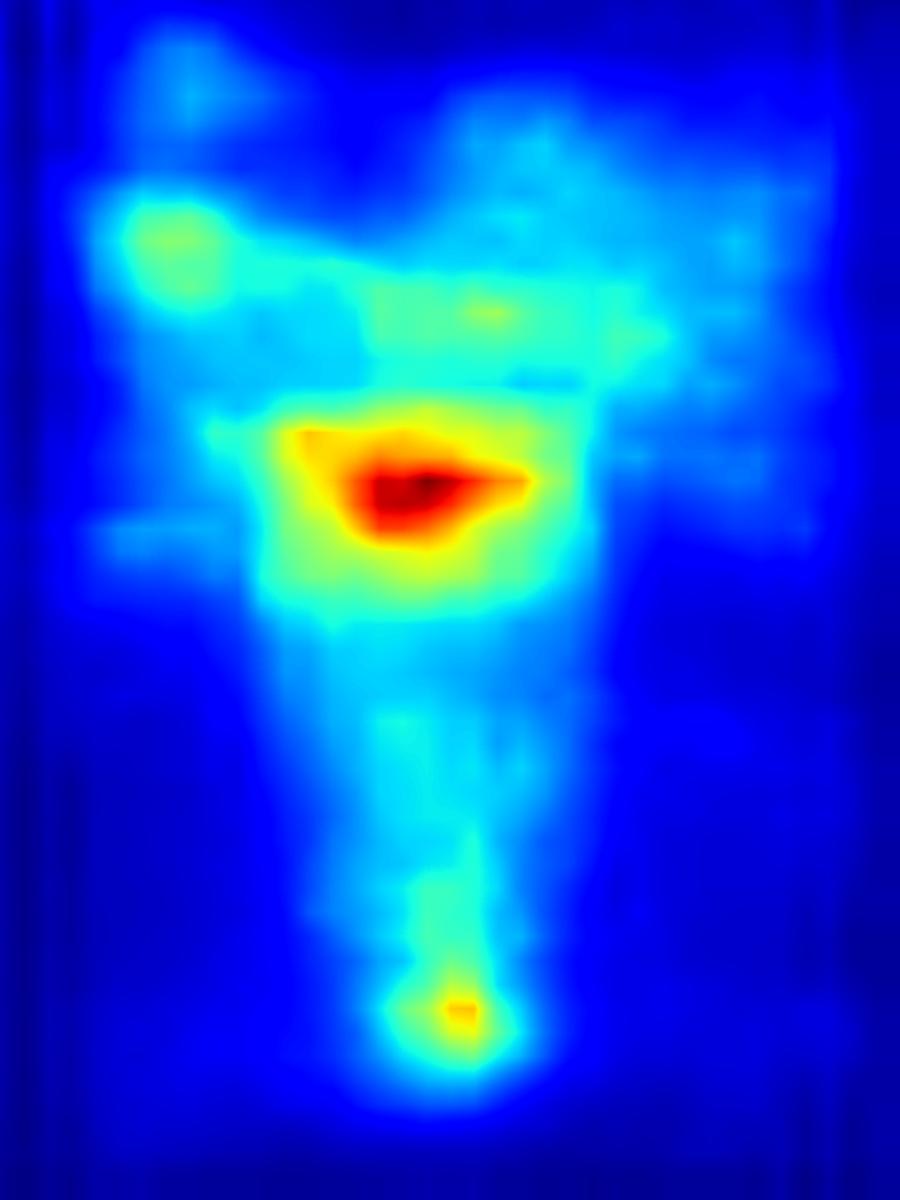
2. Results - reducing saliency
Results for reducing saliency using several differential operators we explored (recolorization, multi-layer convolution, warping, GAN). For each example, we set the target saliency within the masked region (second column from left) to be 0 (zero). Click on each image to view it in larger size.
Recolorization operator:
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result | ||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
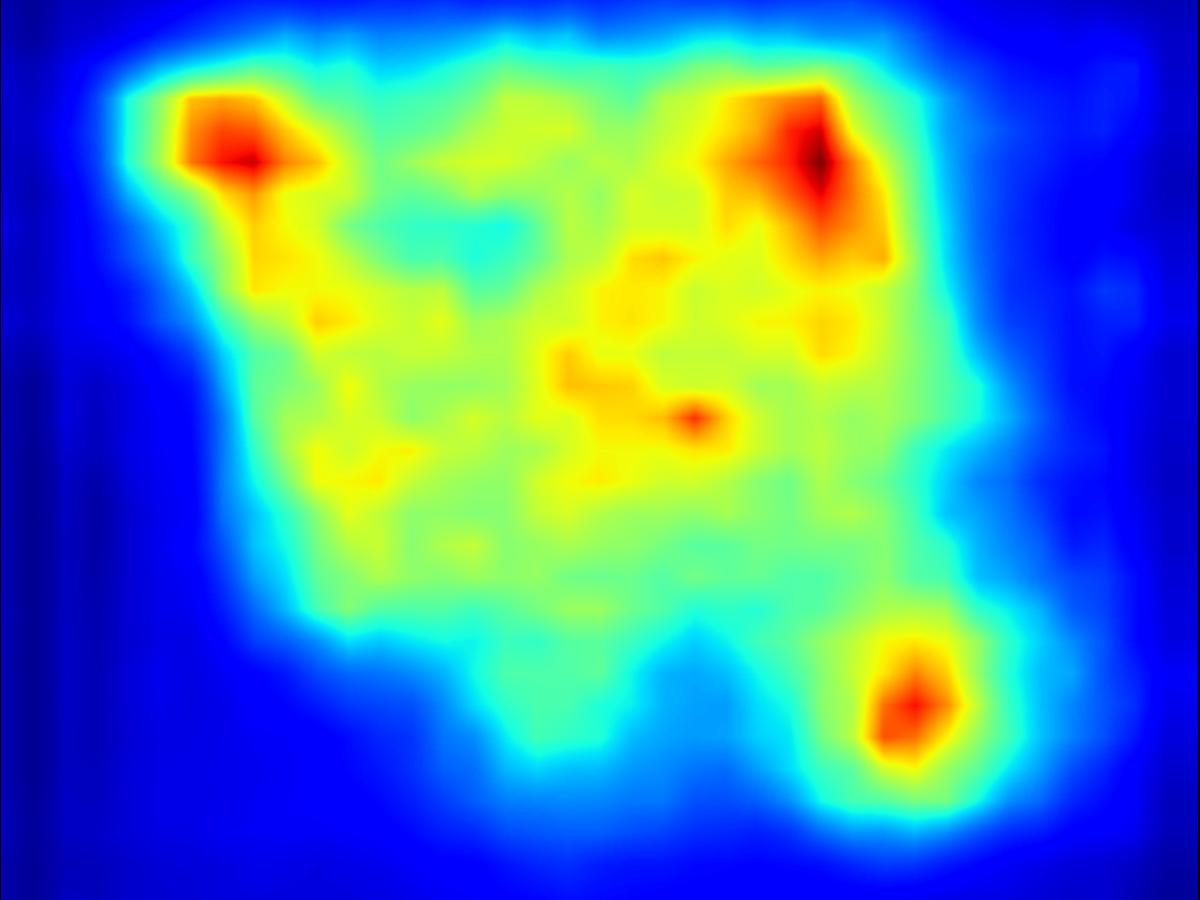 |
 |
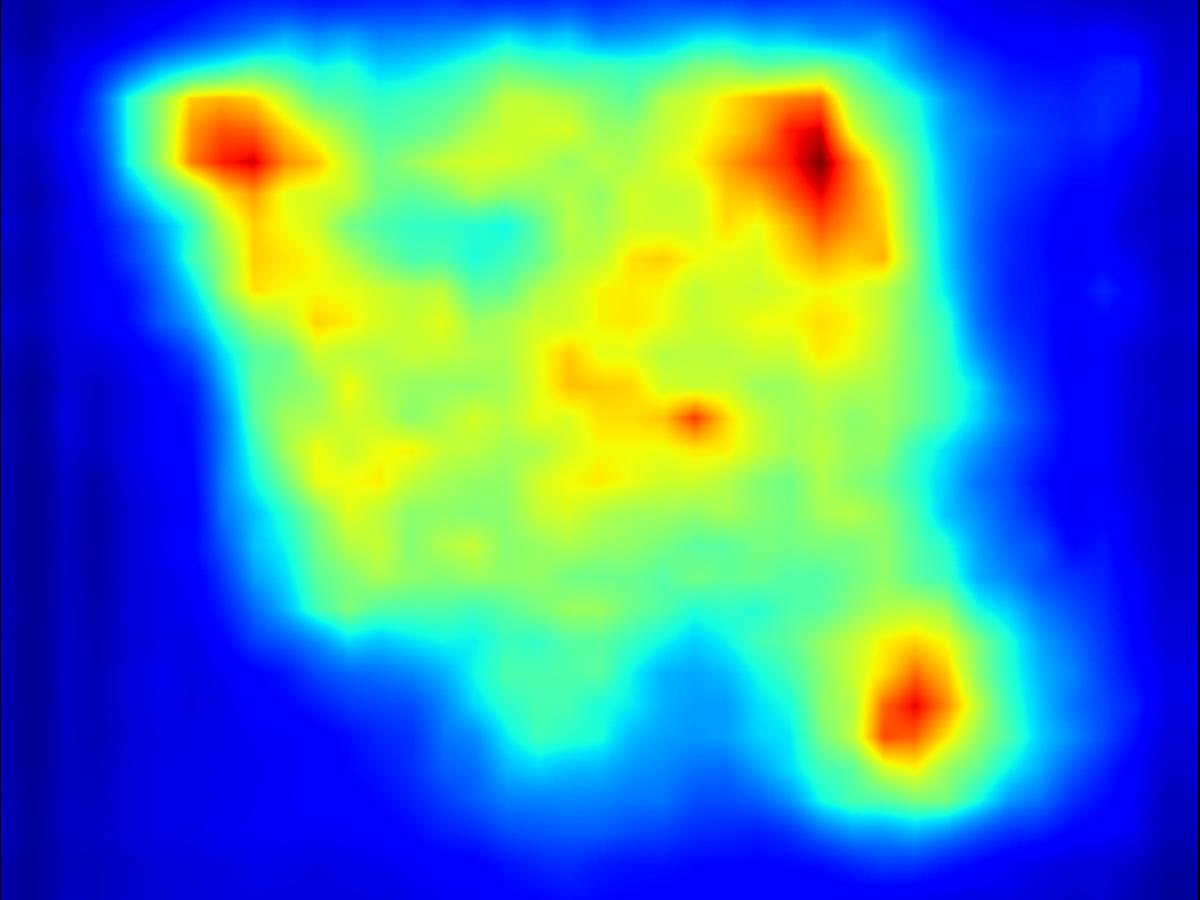 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
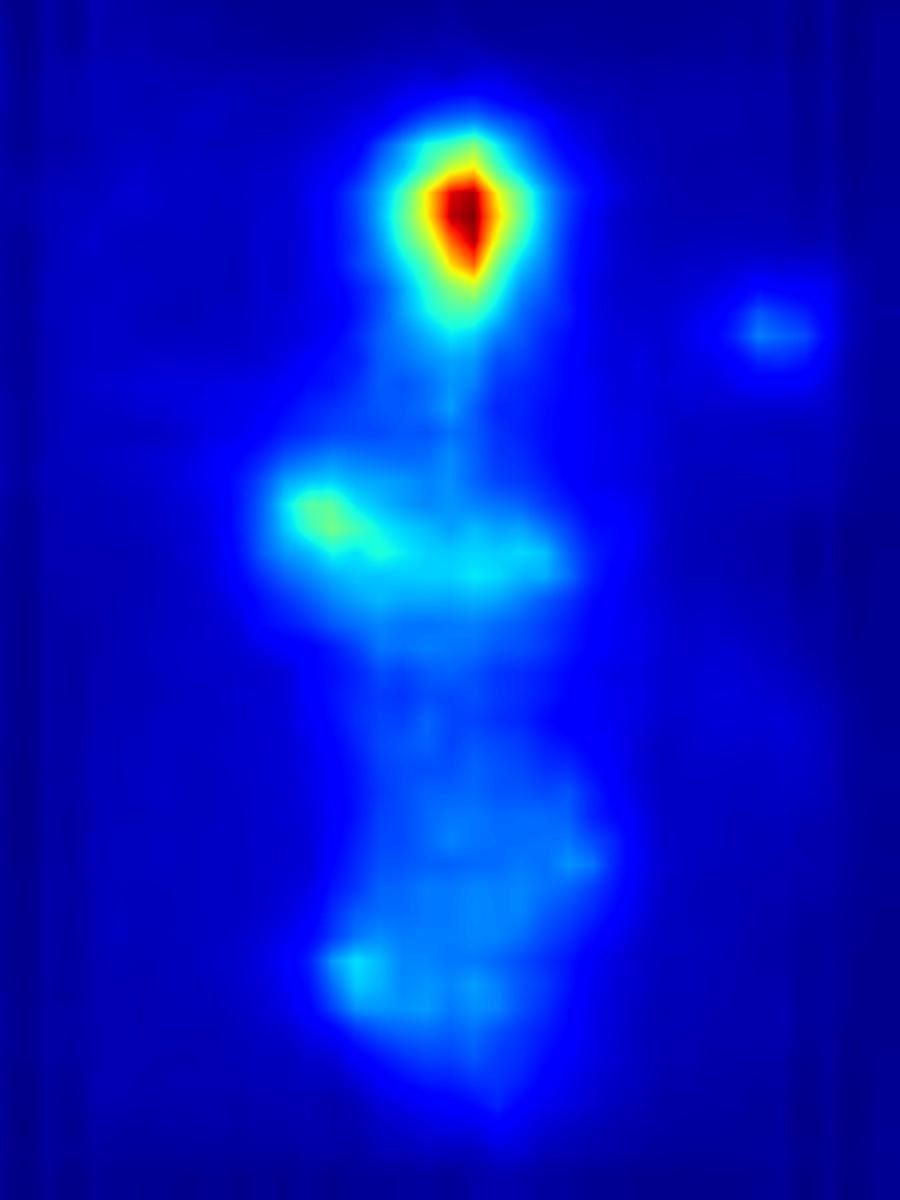 |
 |
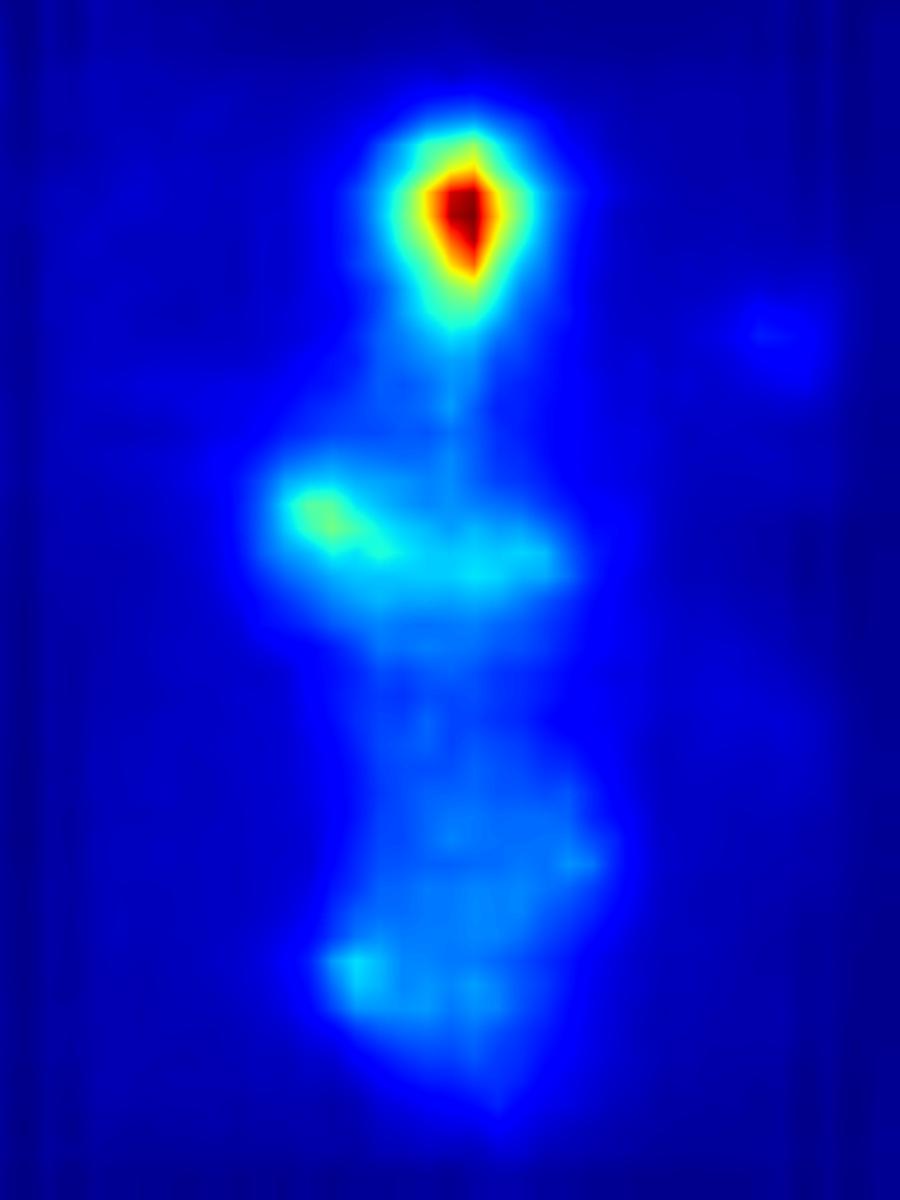 |
||||
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result |
Deep conv operator:
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result | ||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
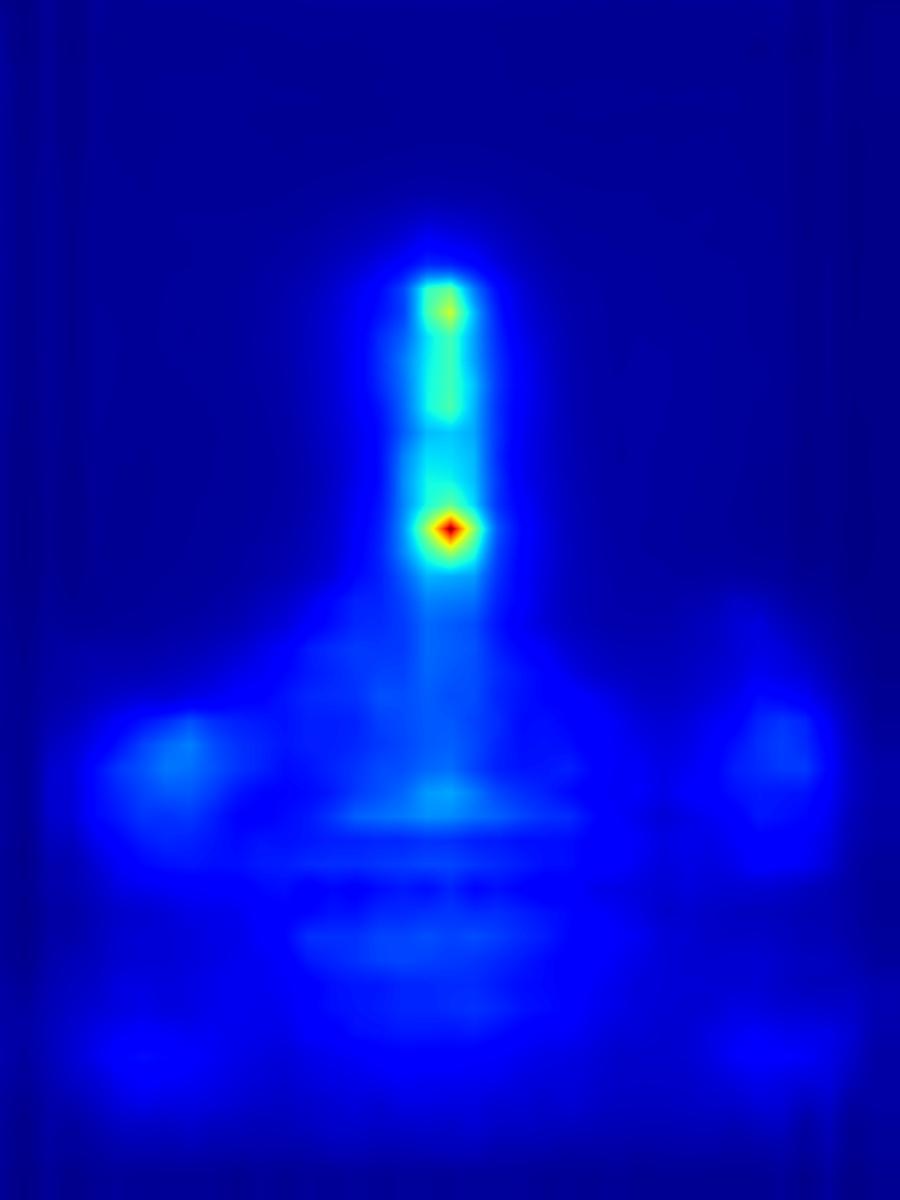 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
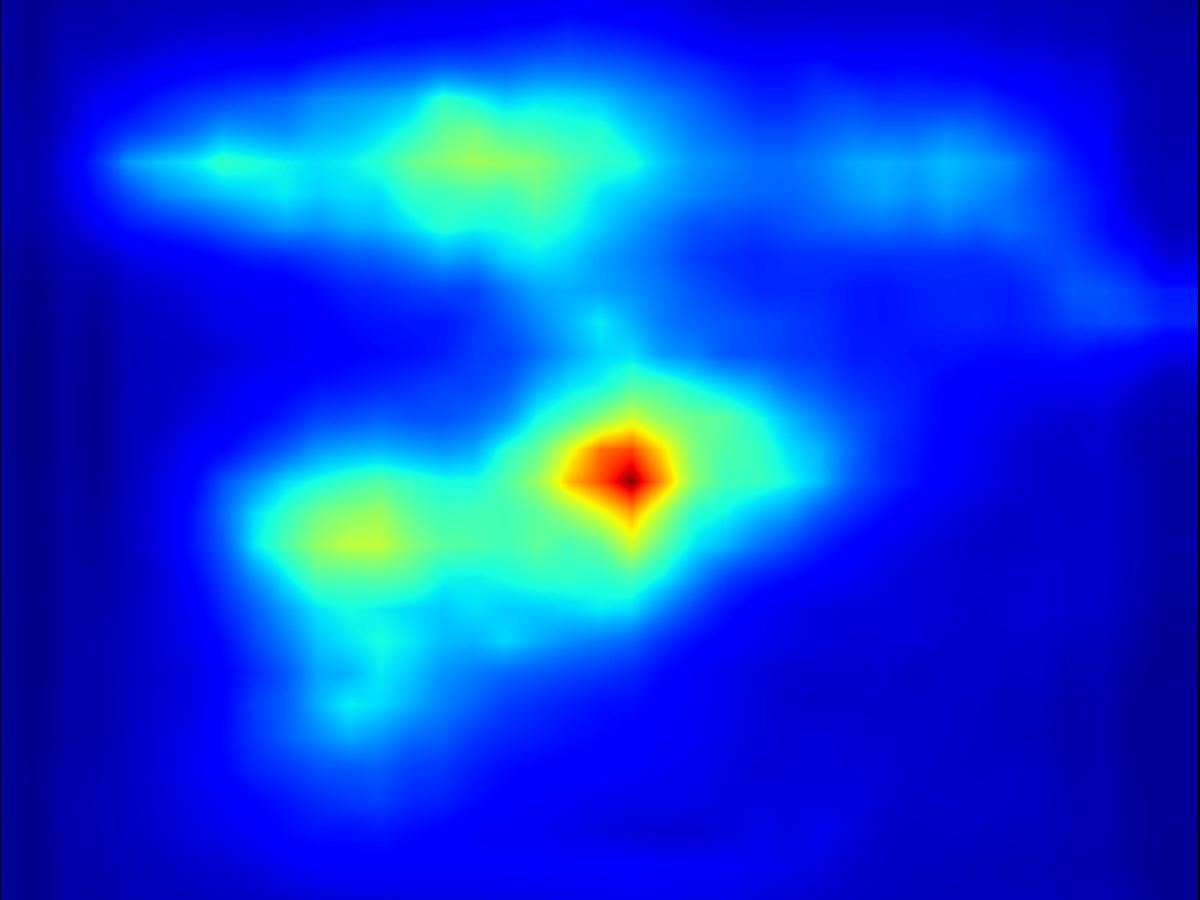 |
 |
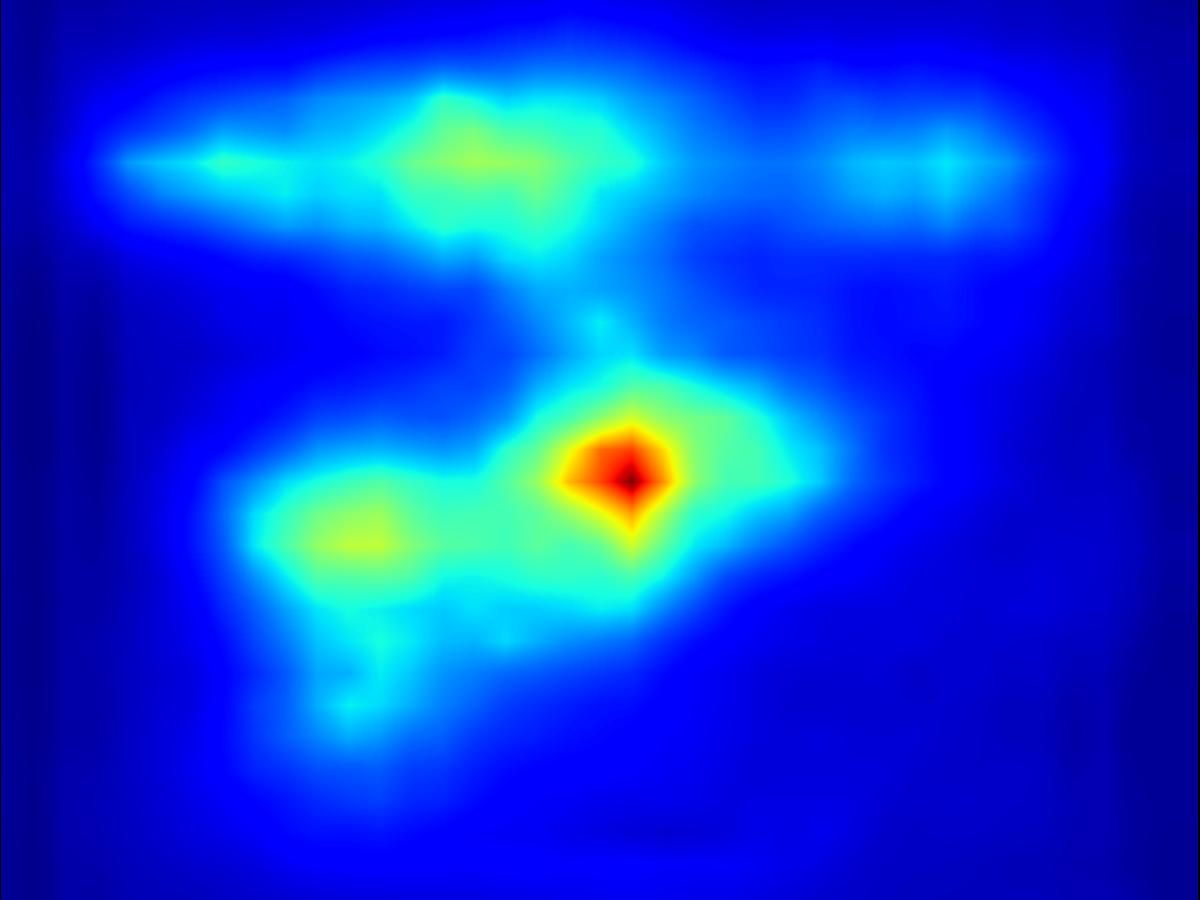 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
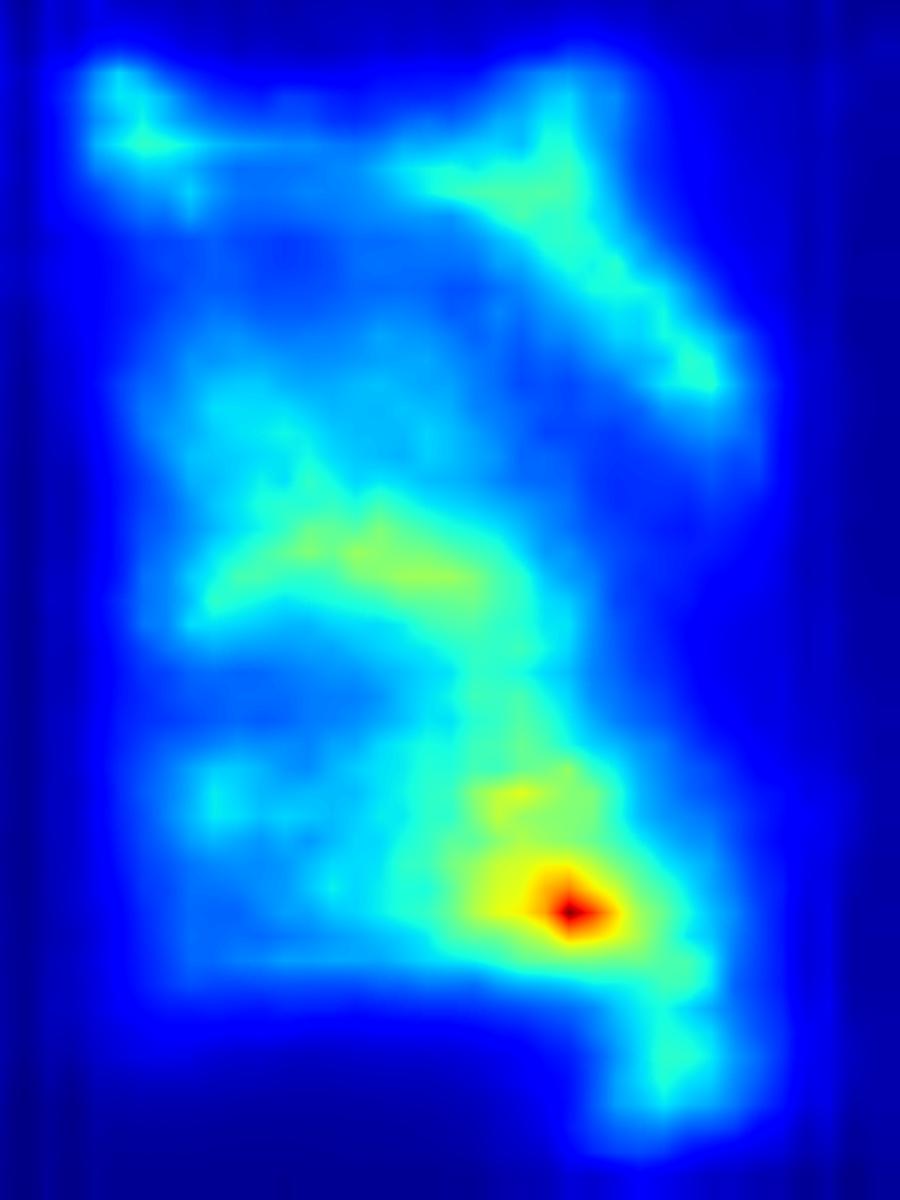 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result |
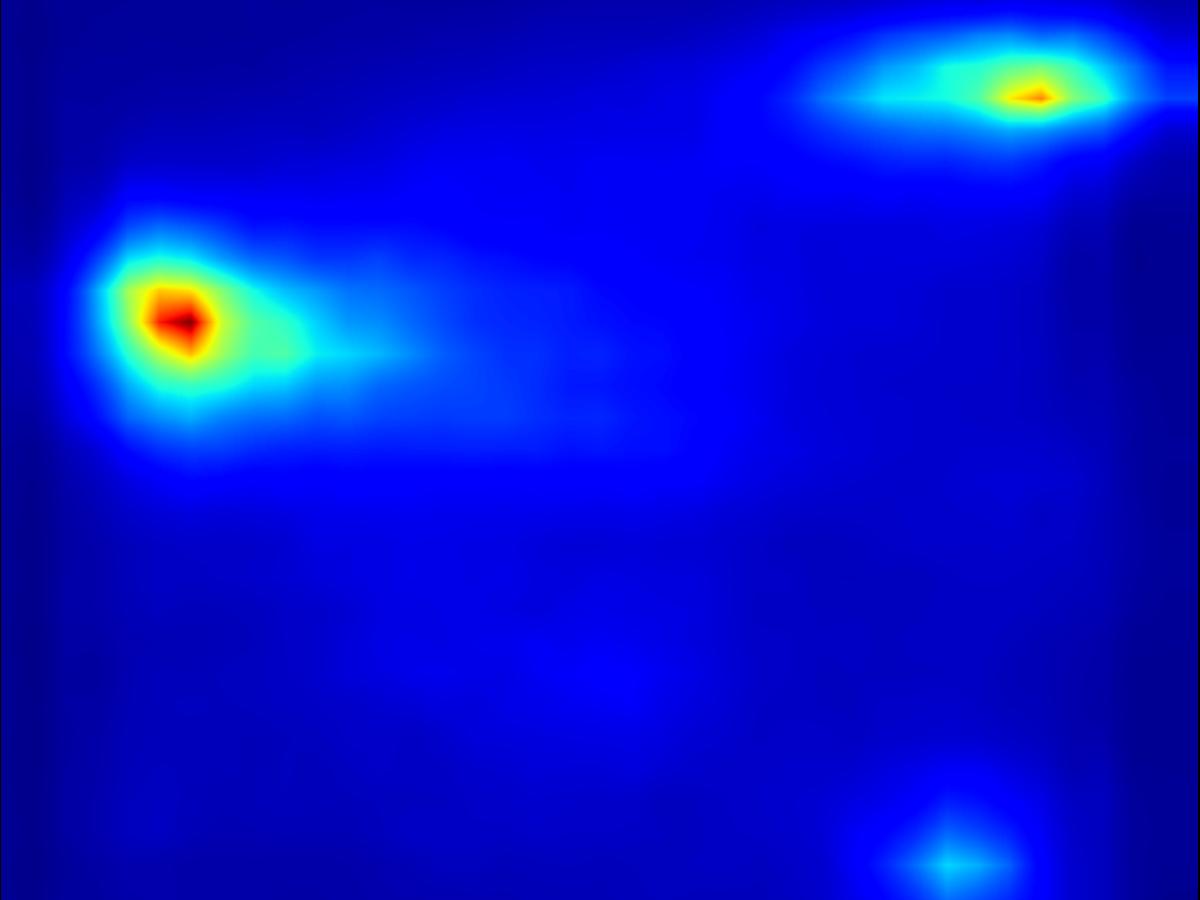
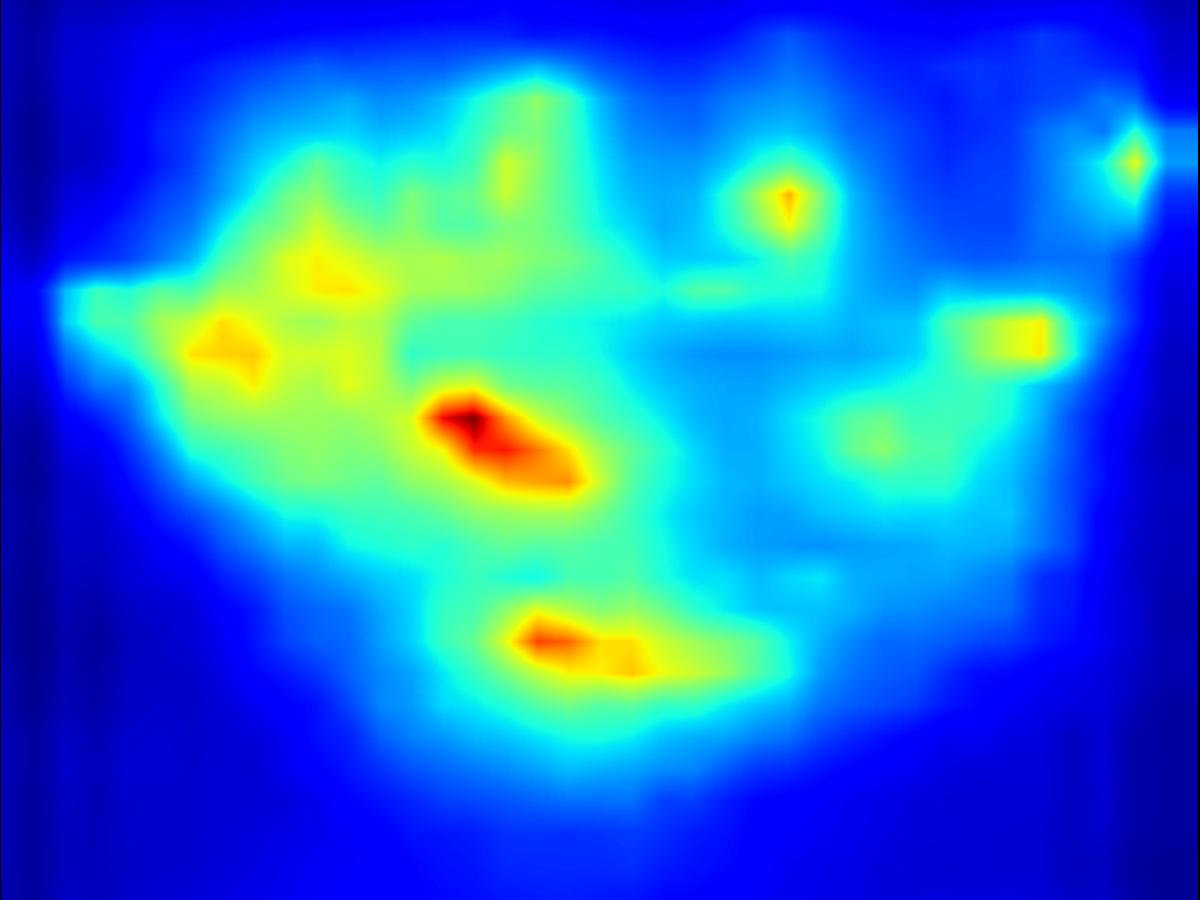
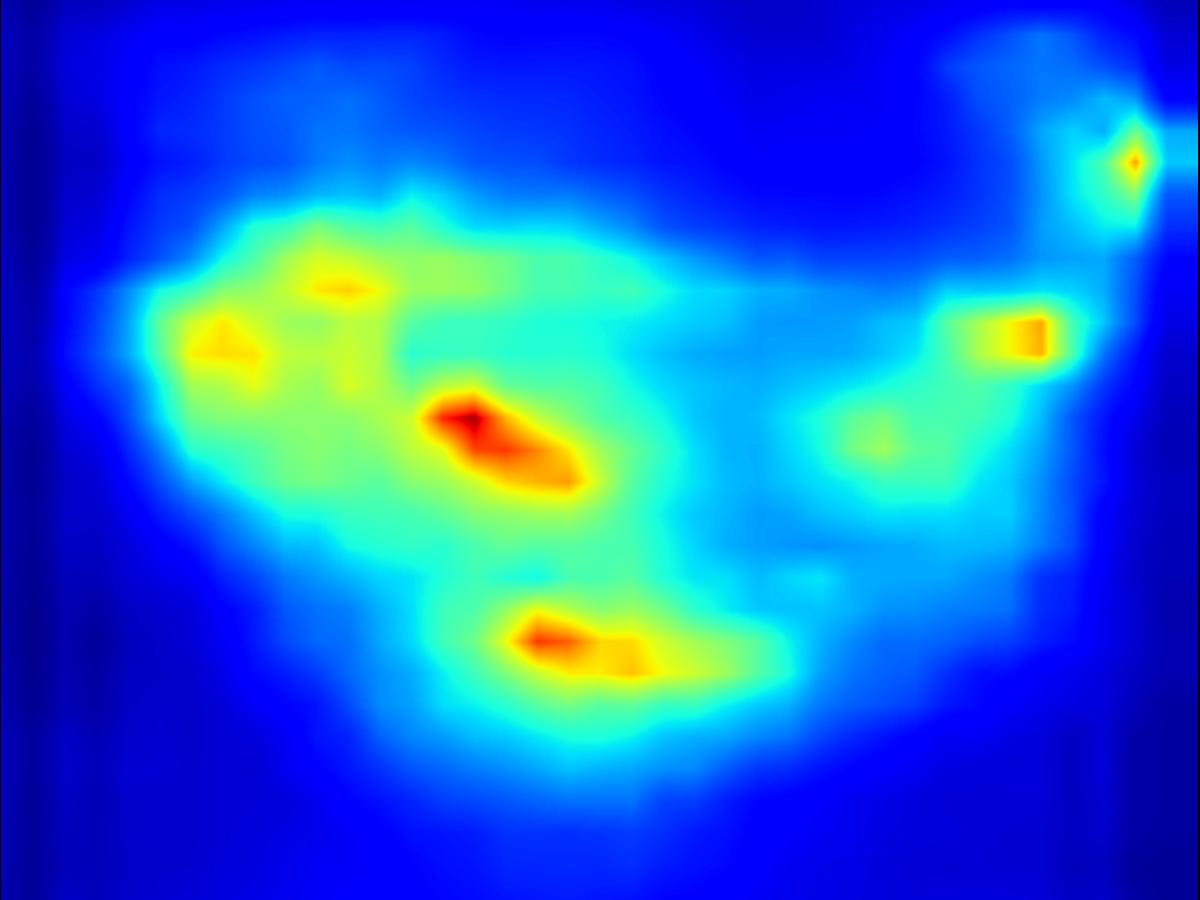
Warping operator:
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result | ||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
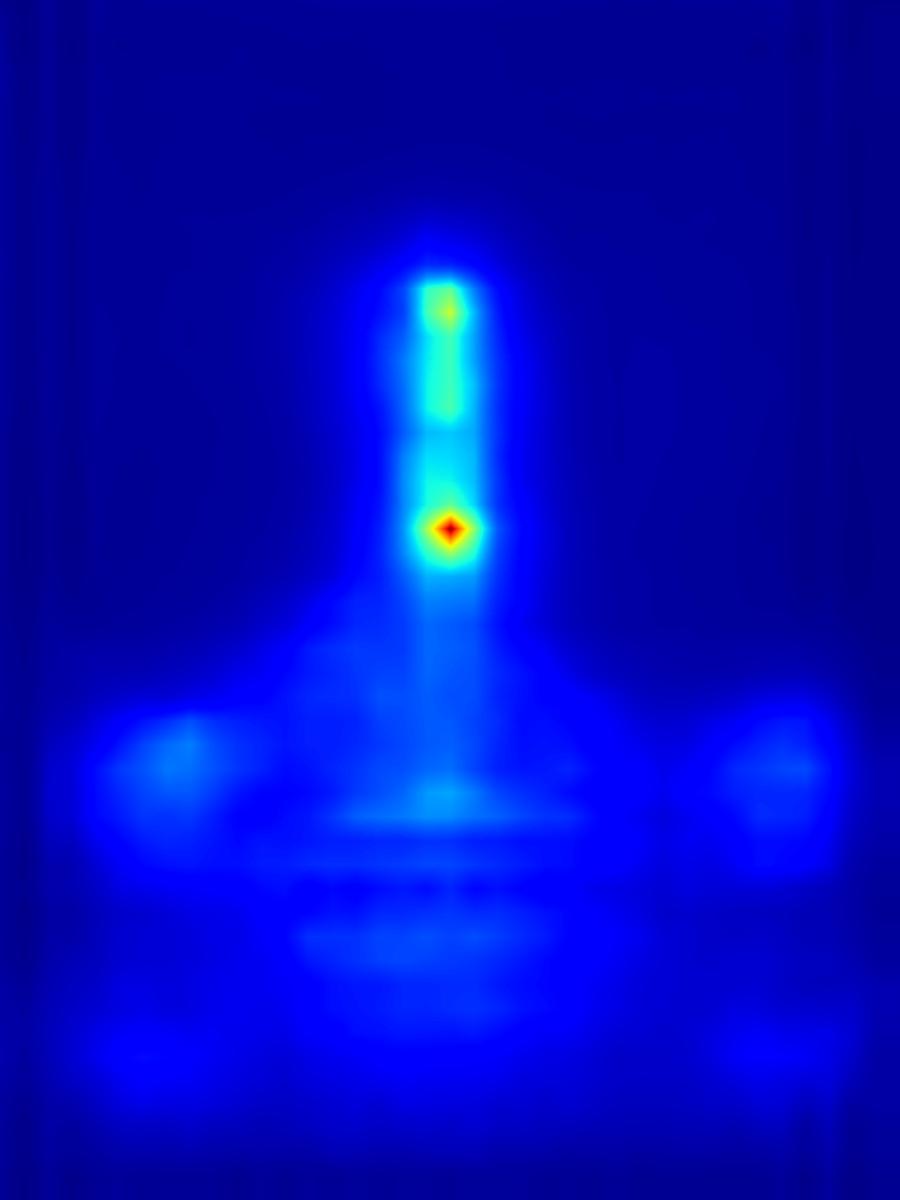 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
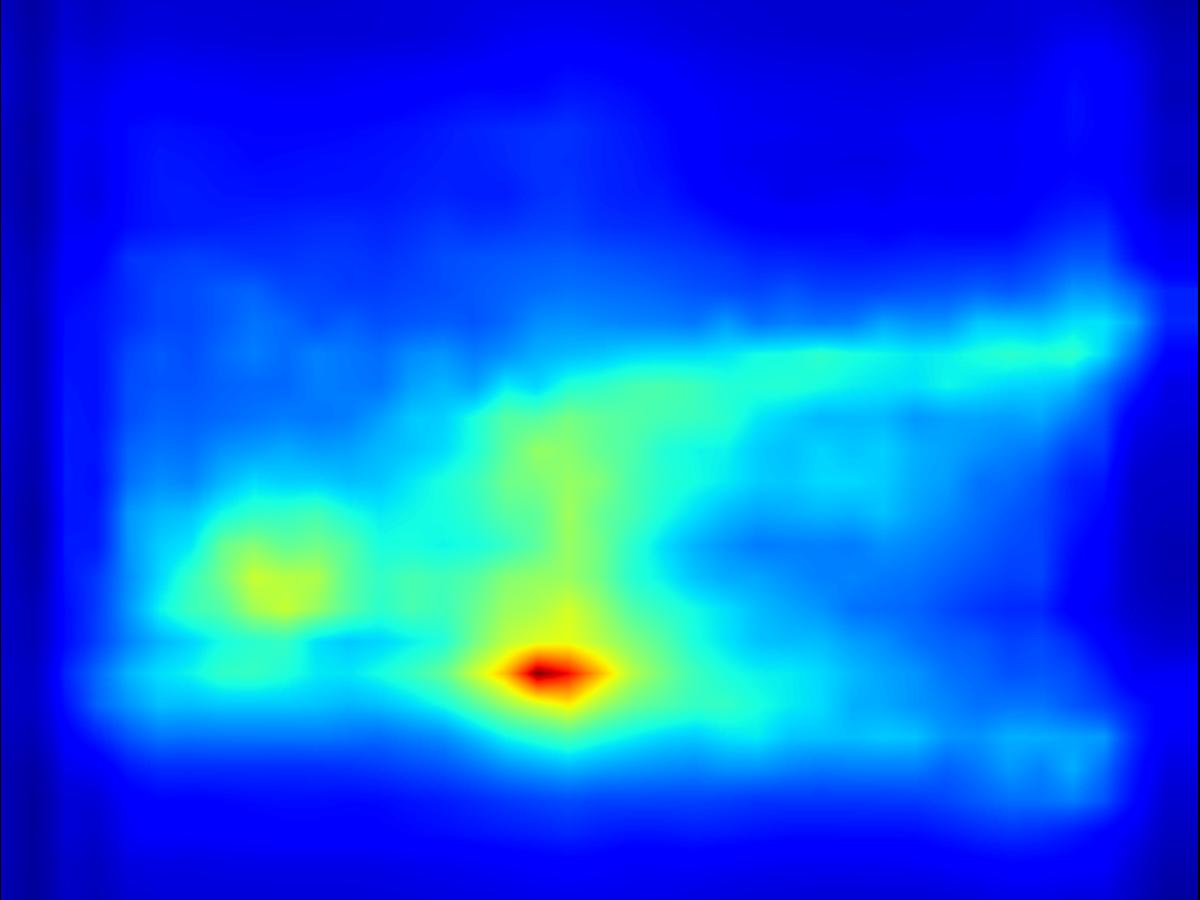 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
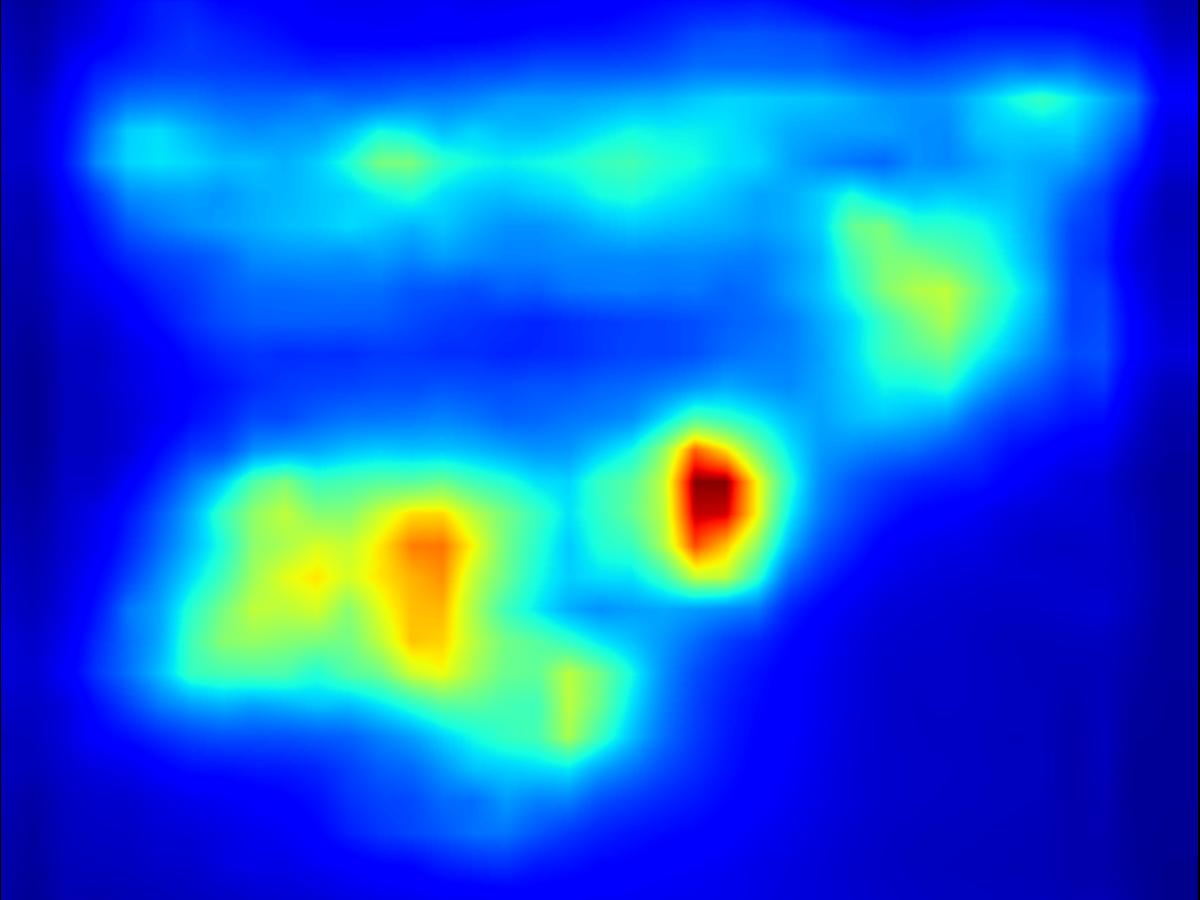 |
 |
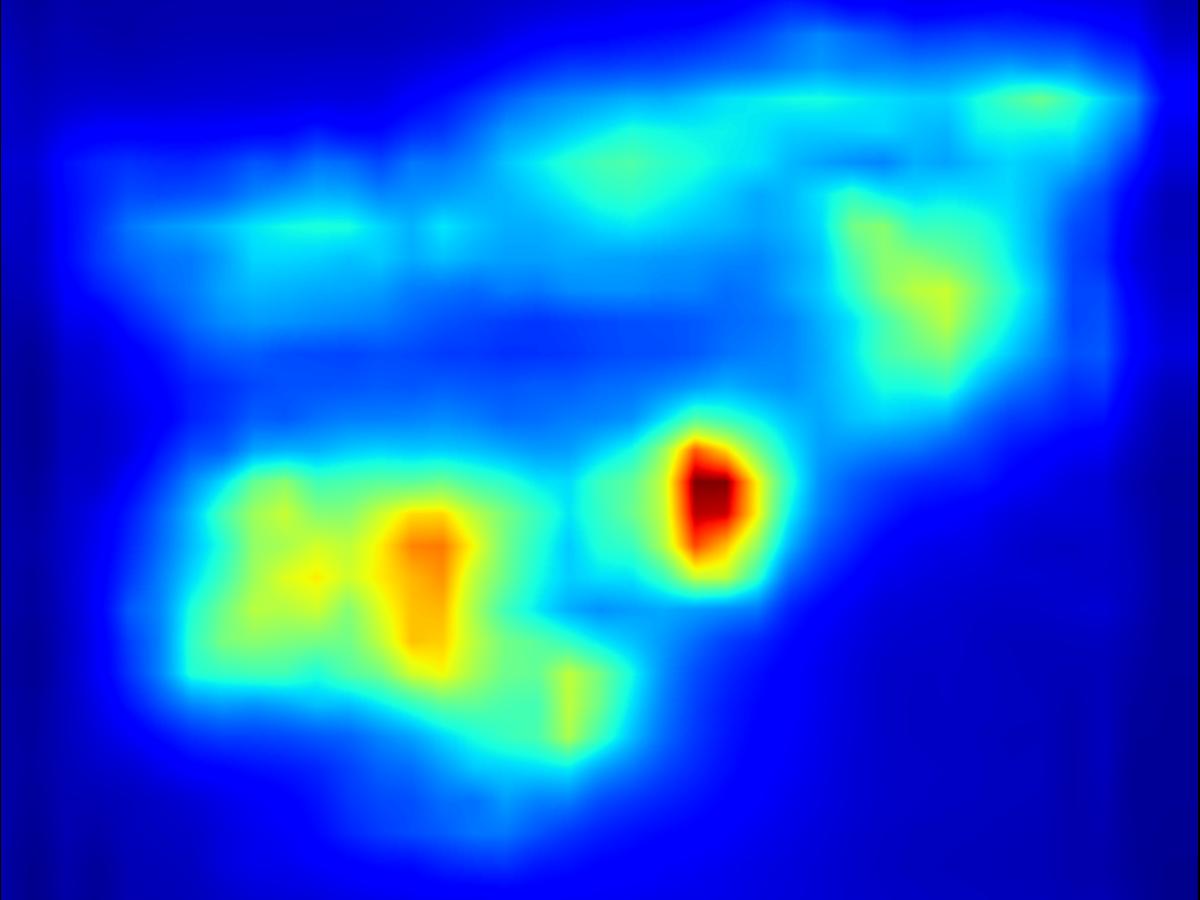 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result |
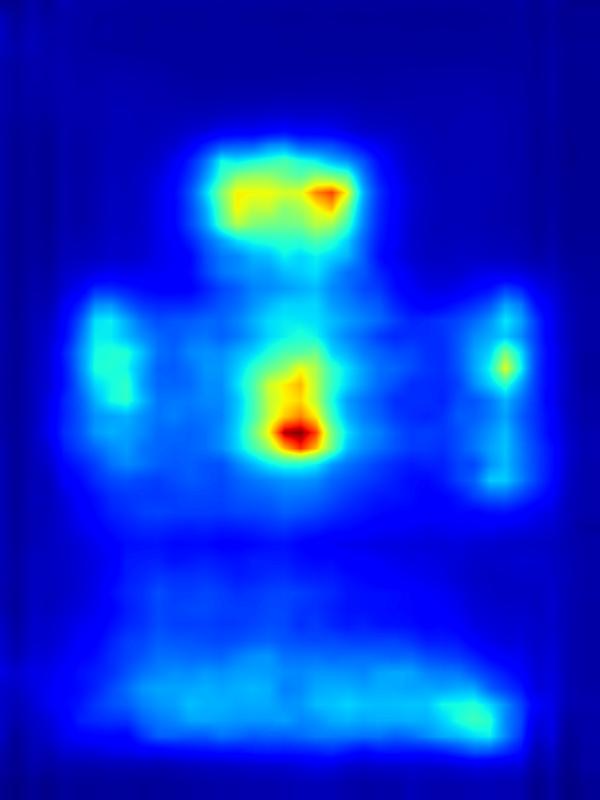
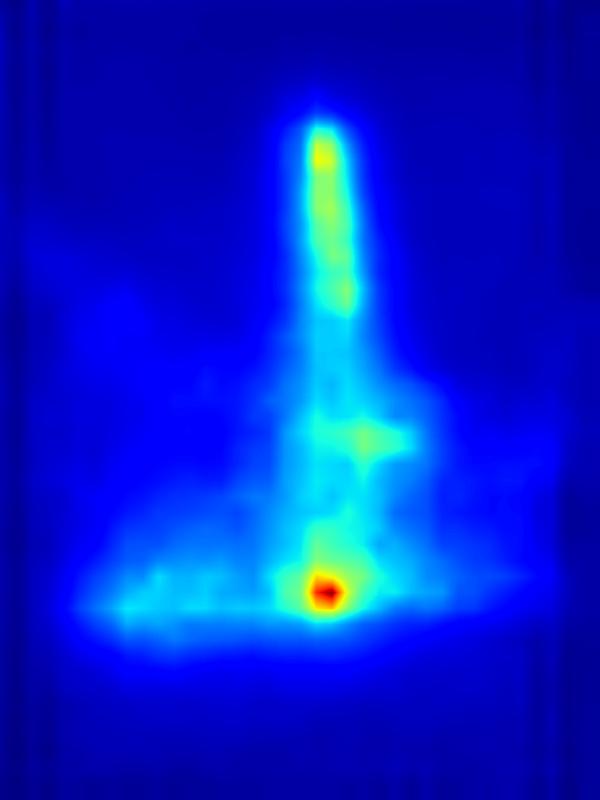
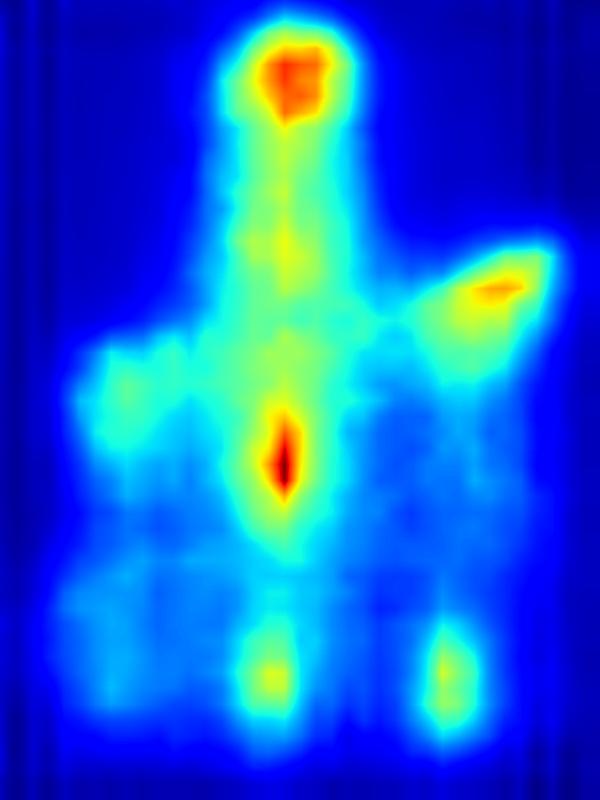
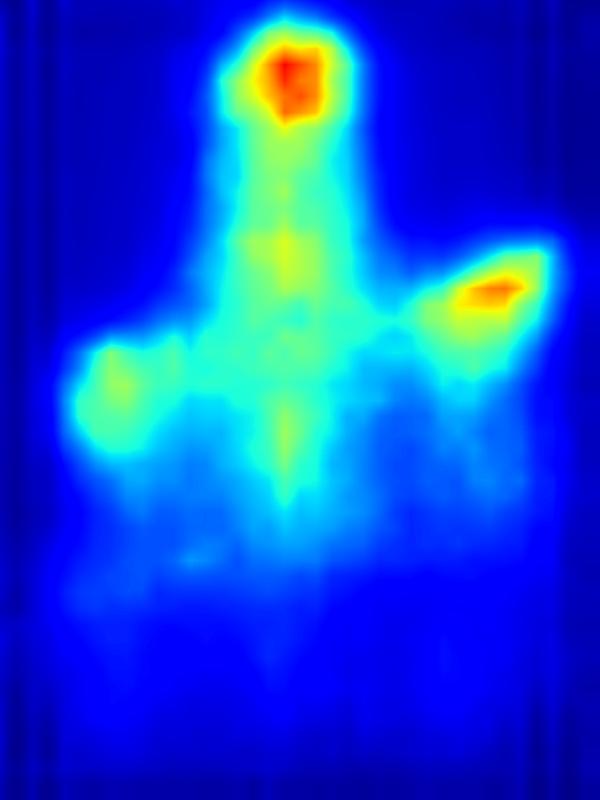
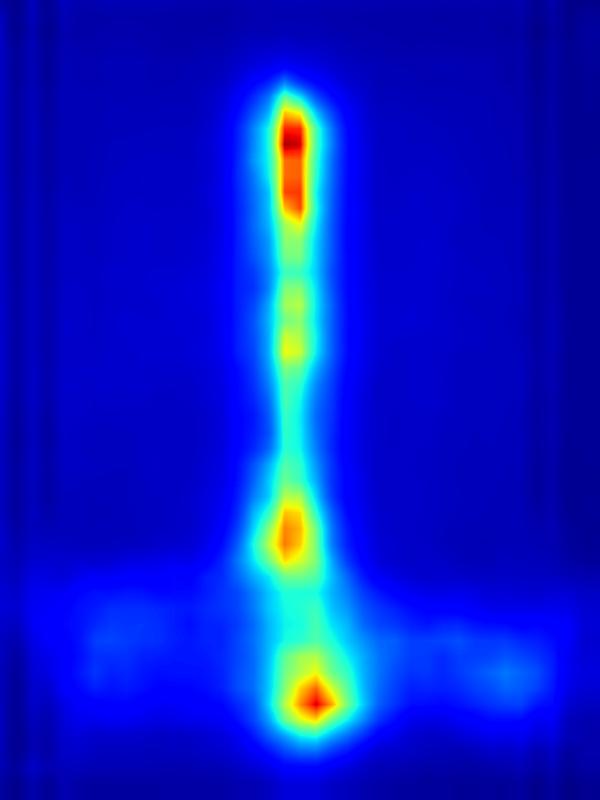
GAN operator:
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result | ||||
 |
 |
 |
 |
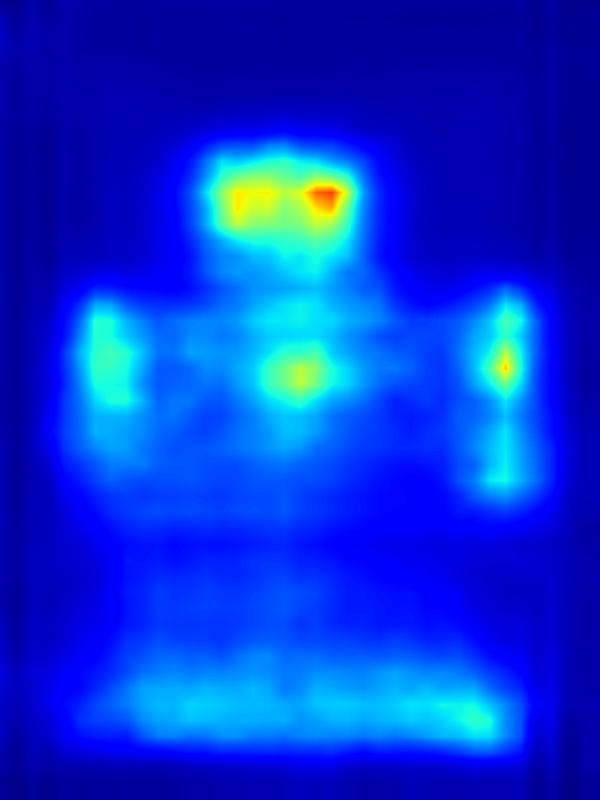 |
||||
 |
 |
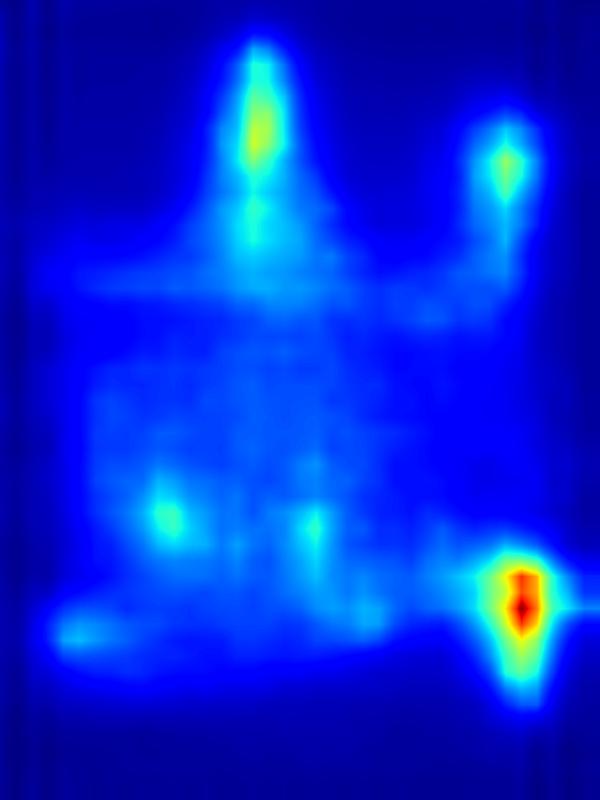 |
 |
 |
||||
 |
 |
 |
 |
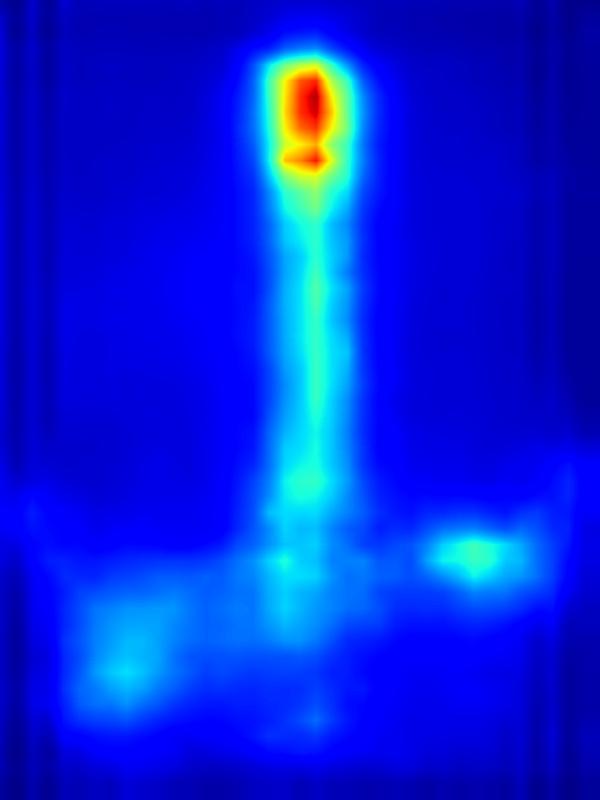 |
||||
 |
 |
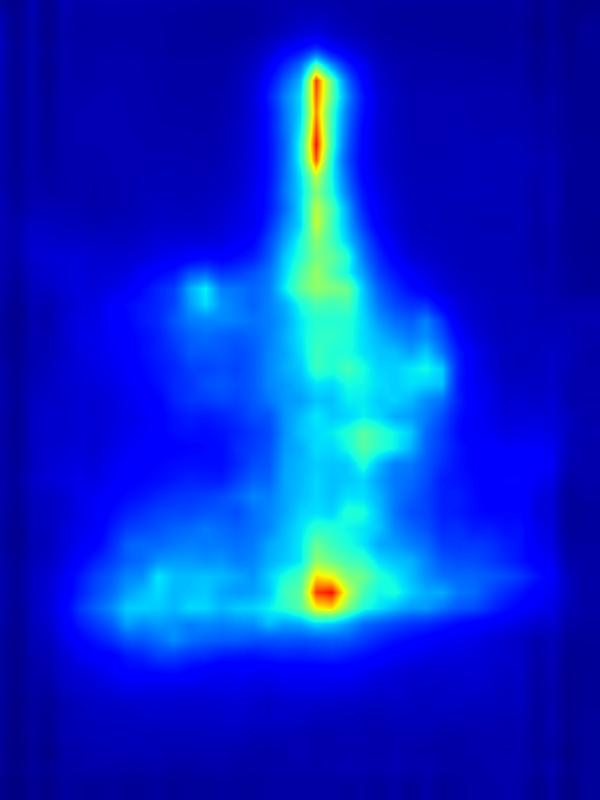 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
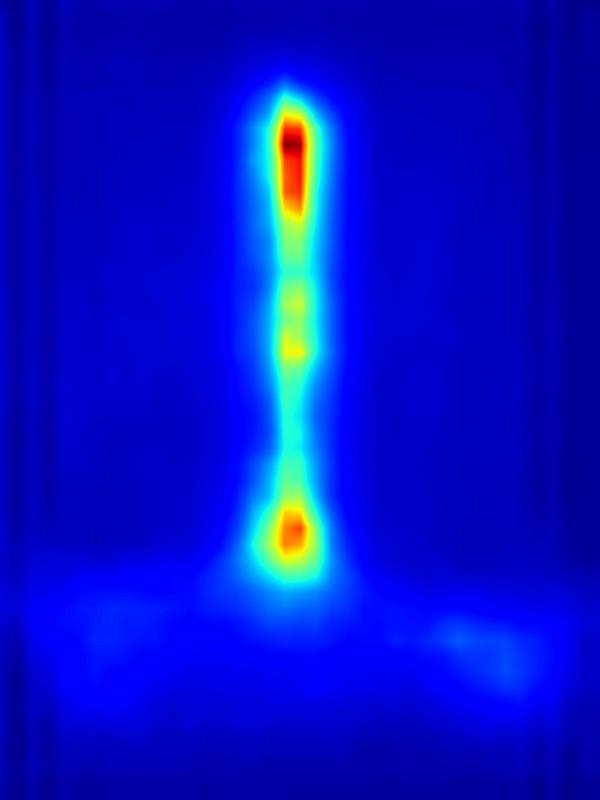 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
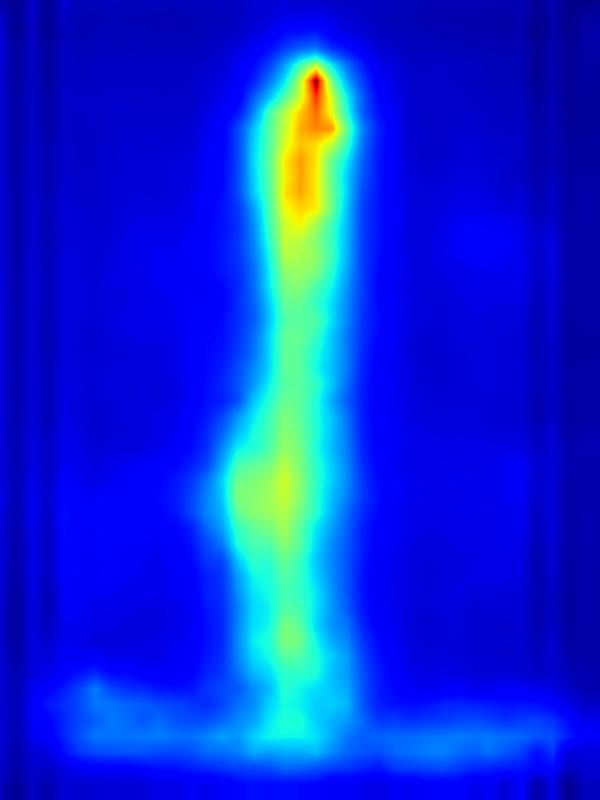 |
 |
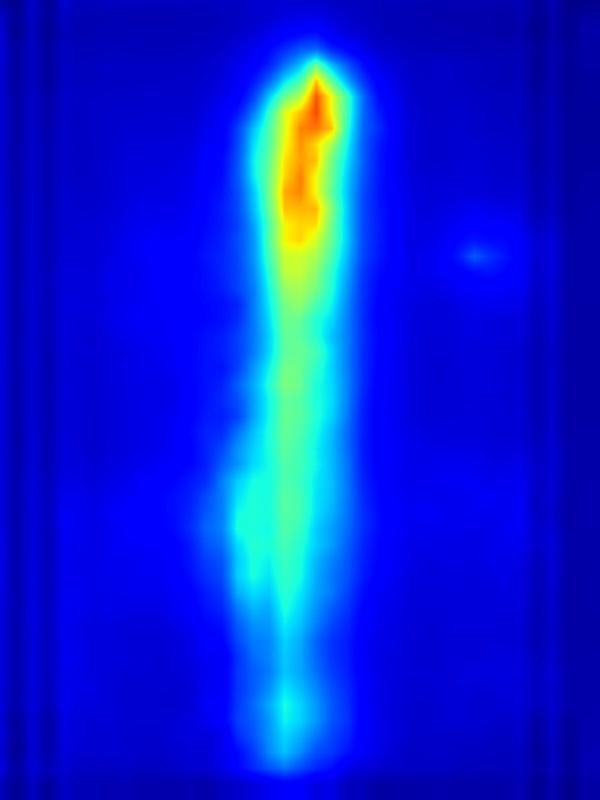 |
||||
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result |
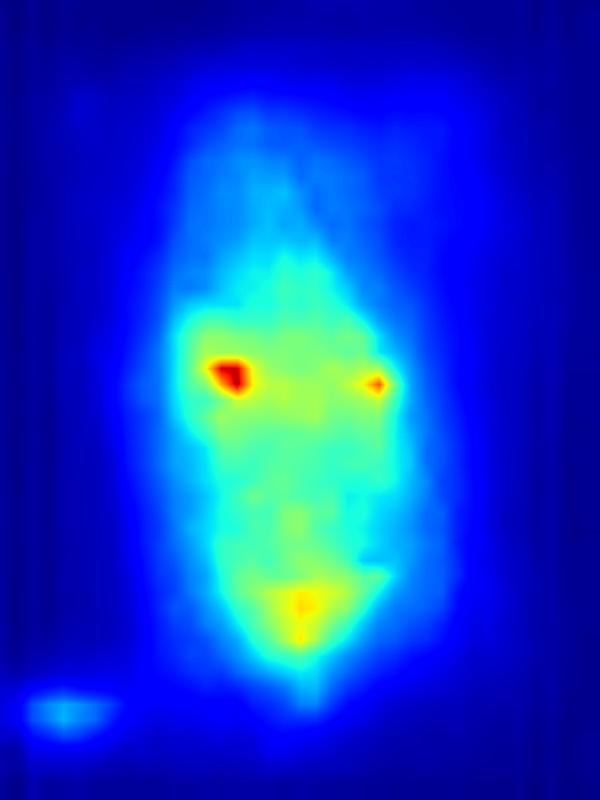
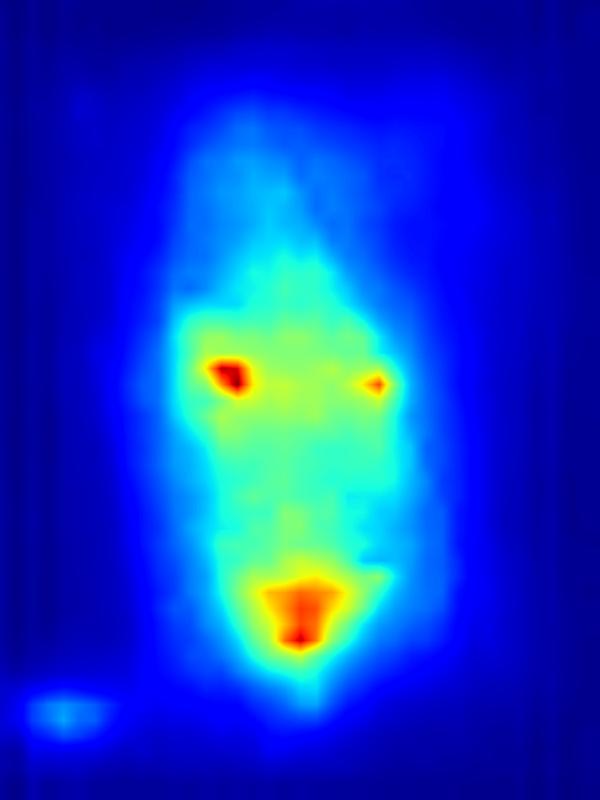
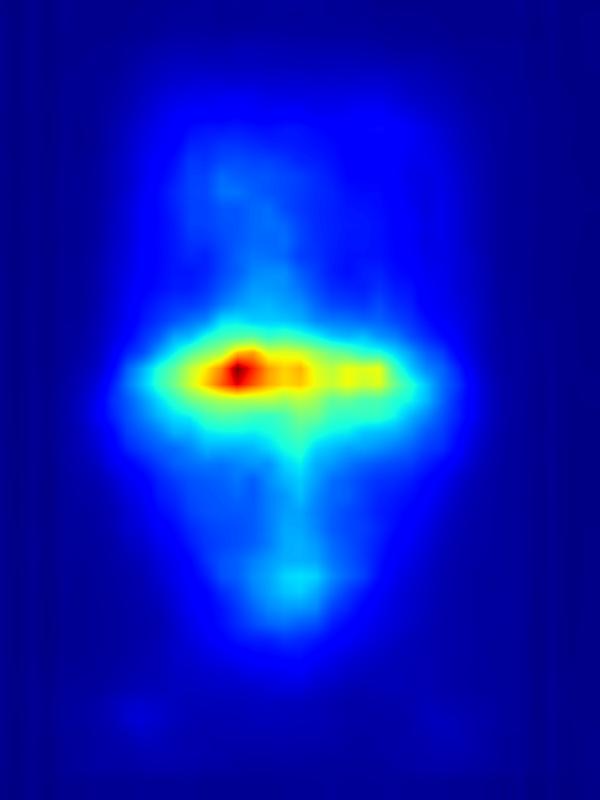
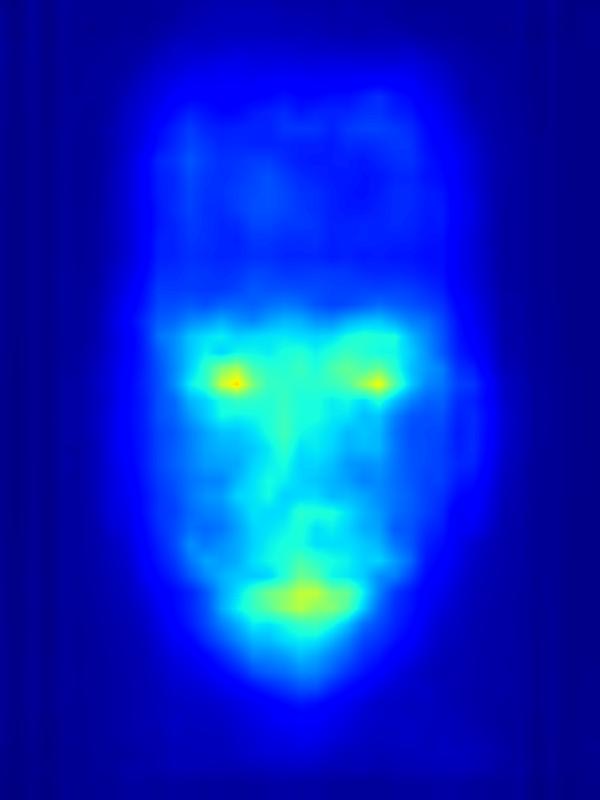
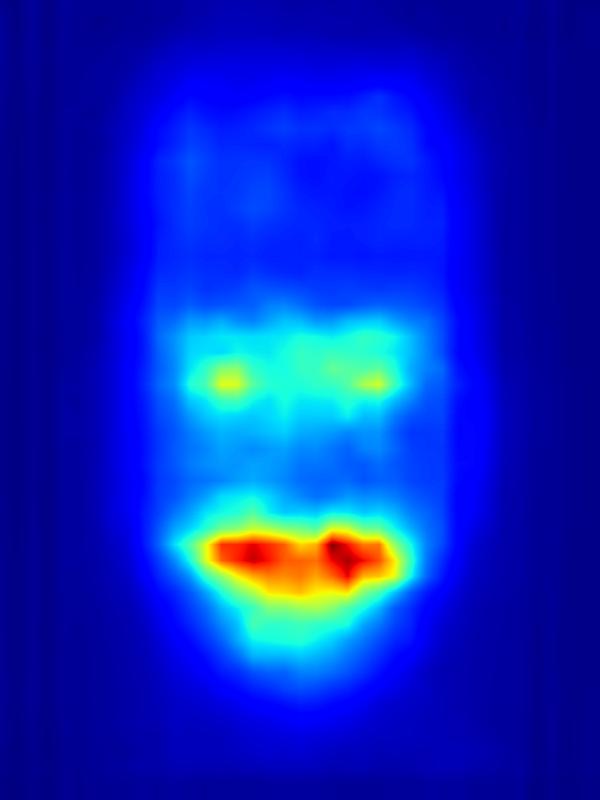
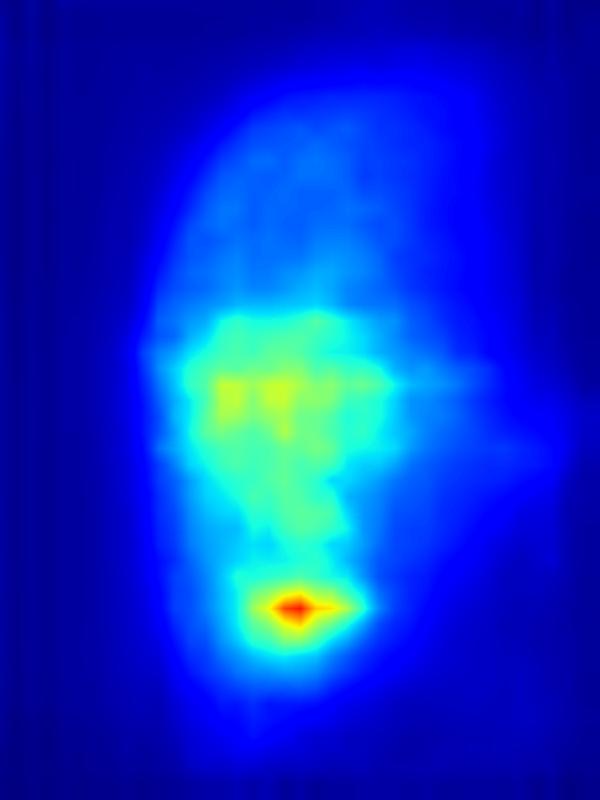
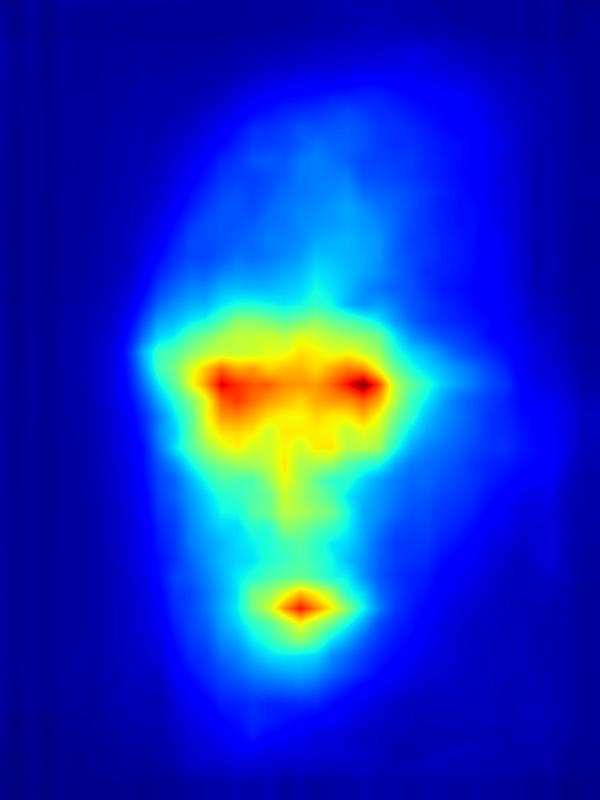
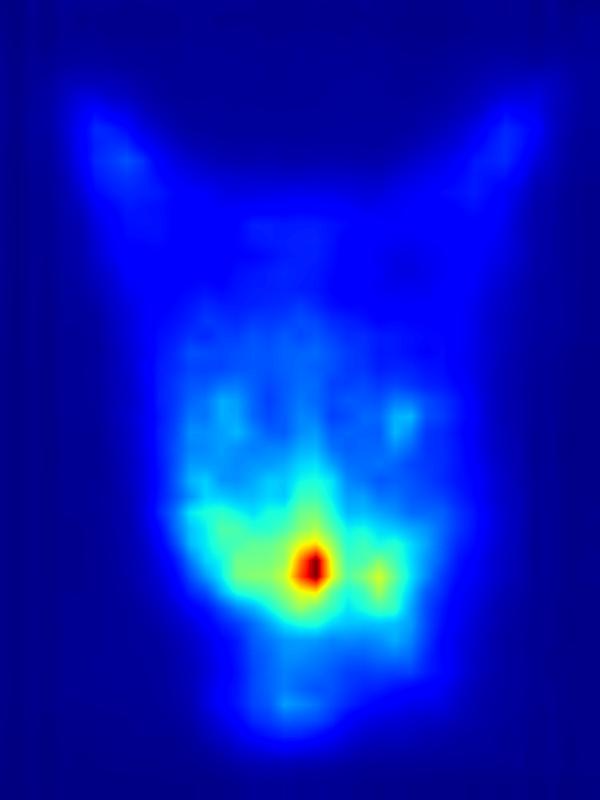
3. Results - Increasing Saliency
Our focus in this paper is on decreasing attention for the purpose of reducing visual distraction. However, we also demonstrate results for increasing attention using the GAN operator. For each example, we set the target saliency within the masked region (second column from left) to be 1. Click on each image to view it in larger size.
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result | ||||
 |
 |
 |
 |
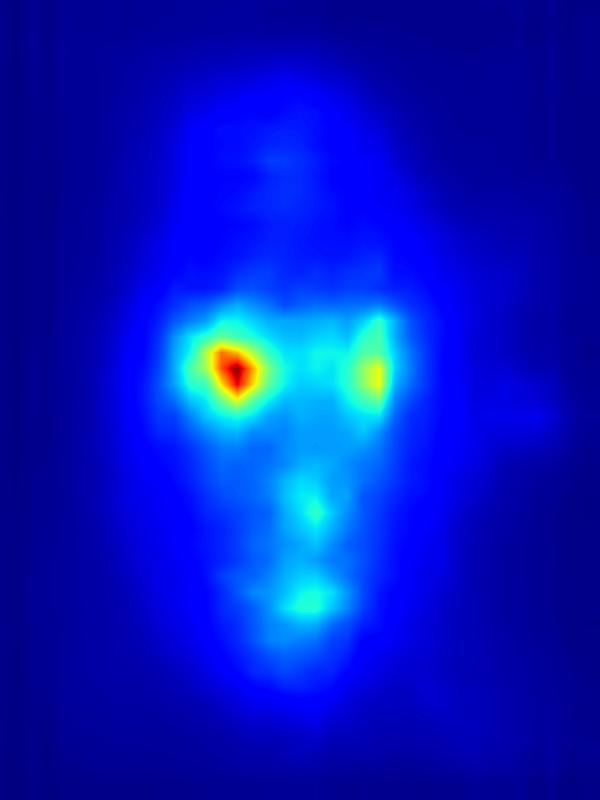 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
 |
||||
 |
 |
 |
 |
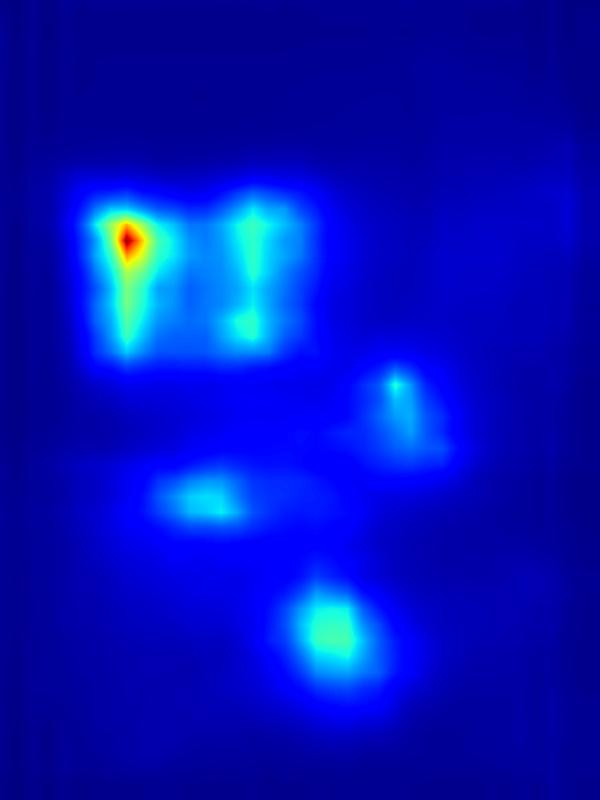 |
||||
 |
 |
 |
 |
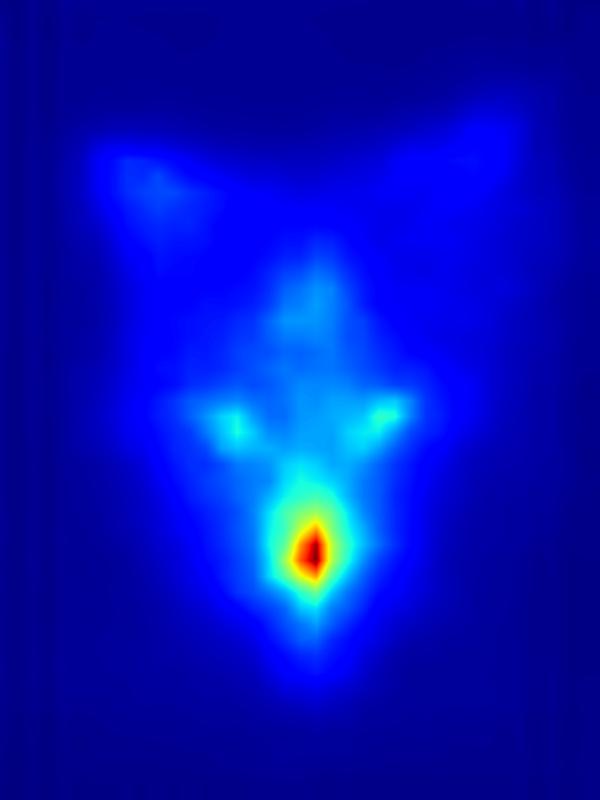 |
||||
 |
 |
 |
 |
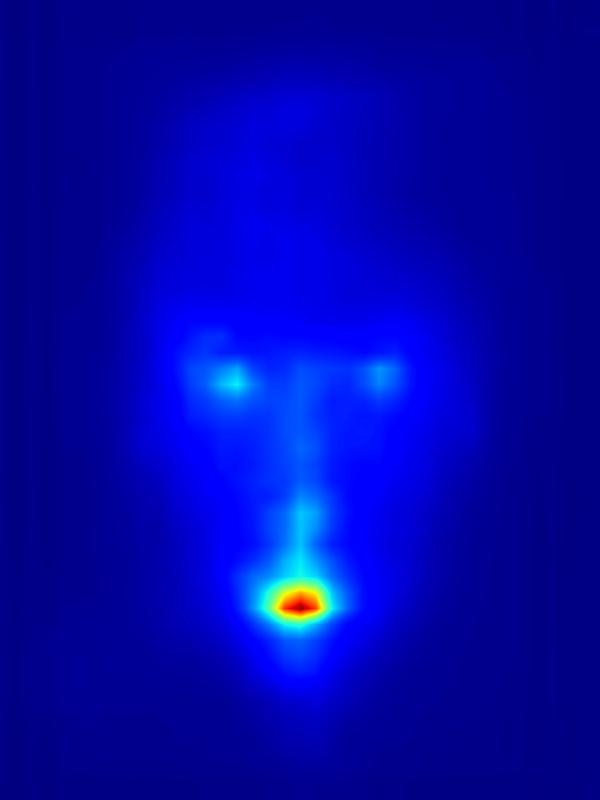 |
||||
 |
 |
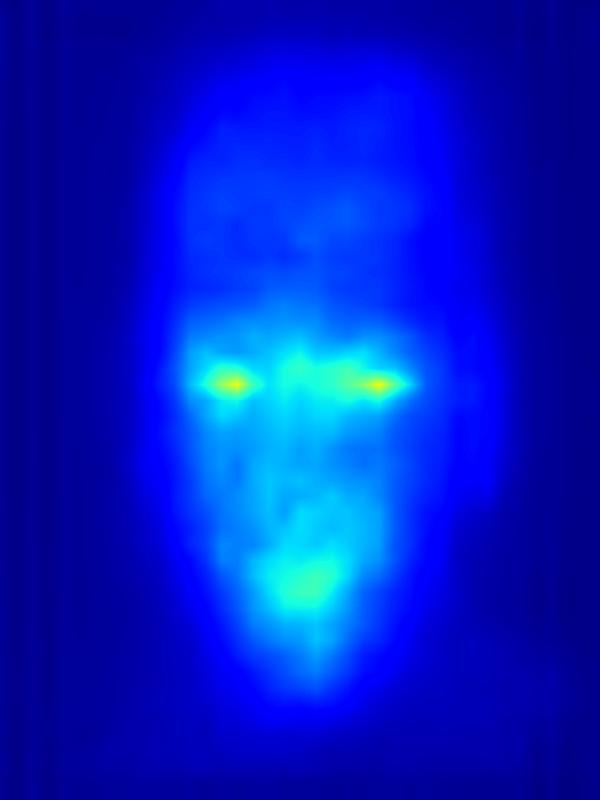 |
 |
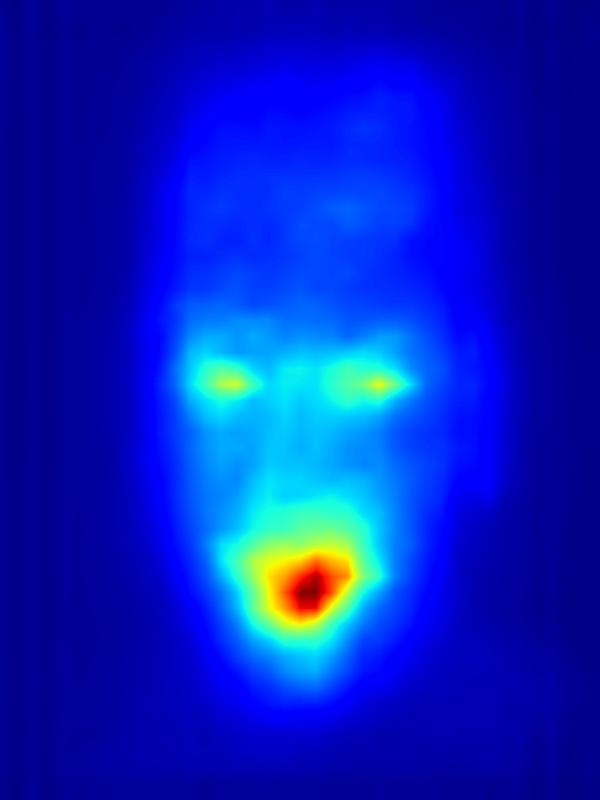 |
||||
 |
 |
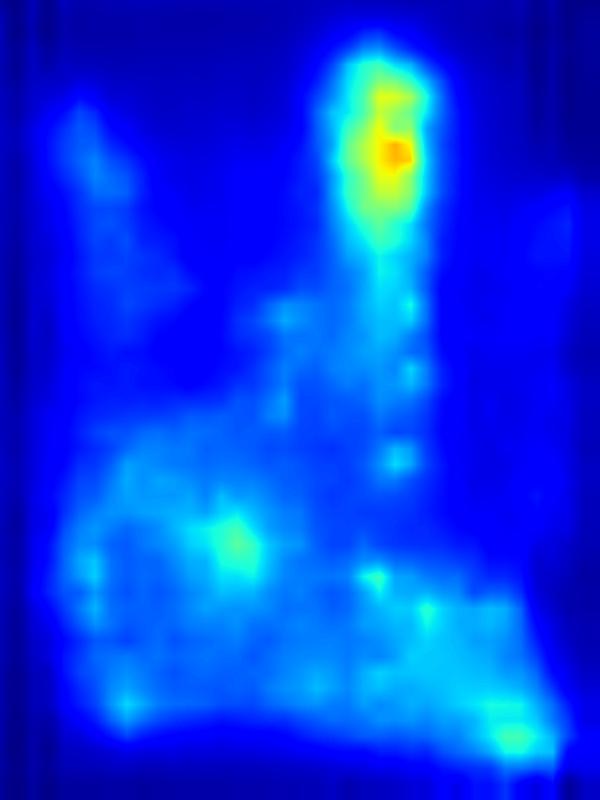 |
 |
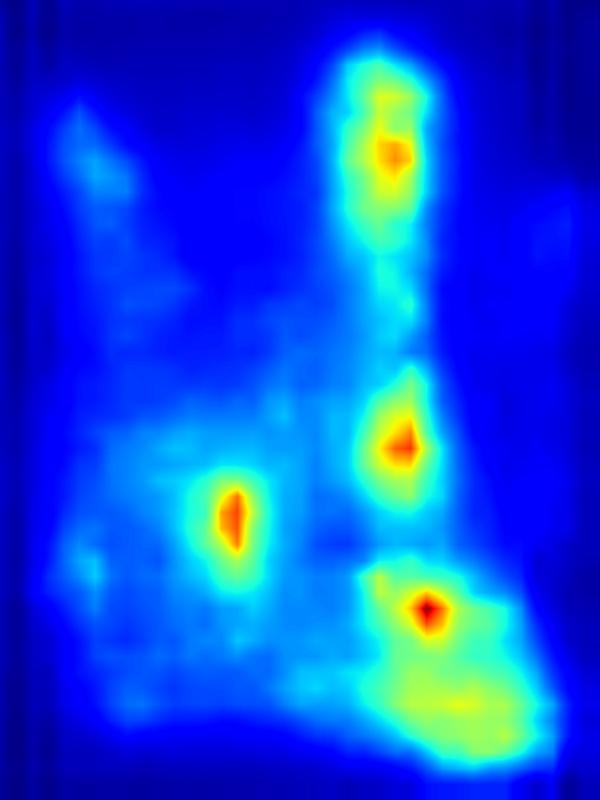 |
||||
| Input | Mask | Predicted saliency of input | Result | Predicted saliency of result |
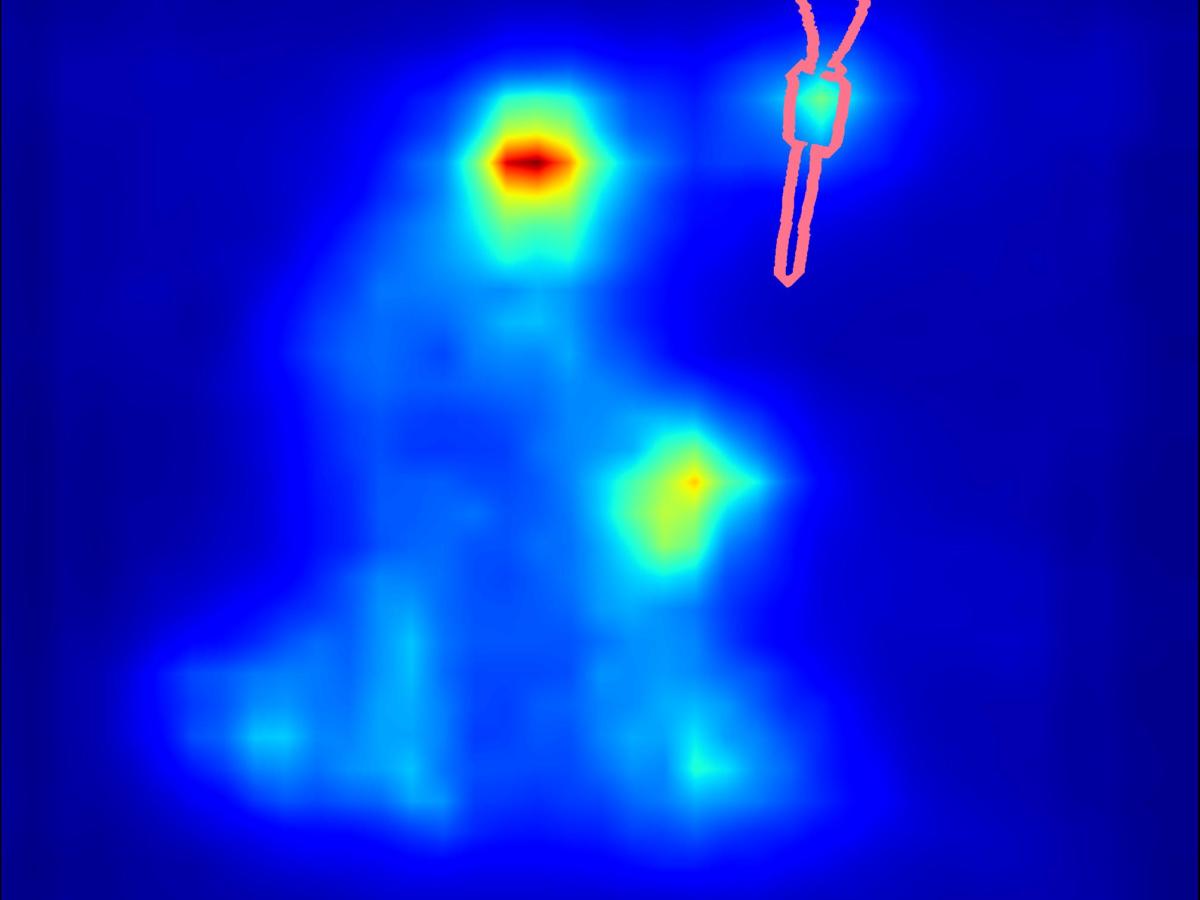
4. Eye-gaze study results
Supplementing Figure 9 in the paper. We show more examples of real eye-gaze saliency maps measured in our perceptual study (see more details on the study in the supplementary PDF).
Saliency decrease:
| Input | Computed Saliency on Input | Measured eye-gaze on Input | Result | Computed Saliency on Result | Measured eye-gaze on Result | |||||
 |
 |
 |
 |
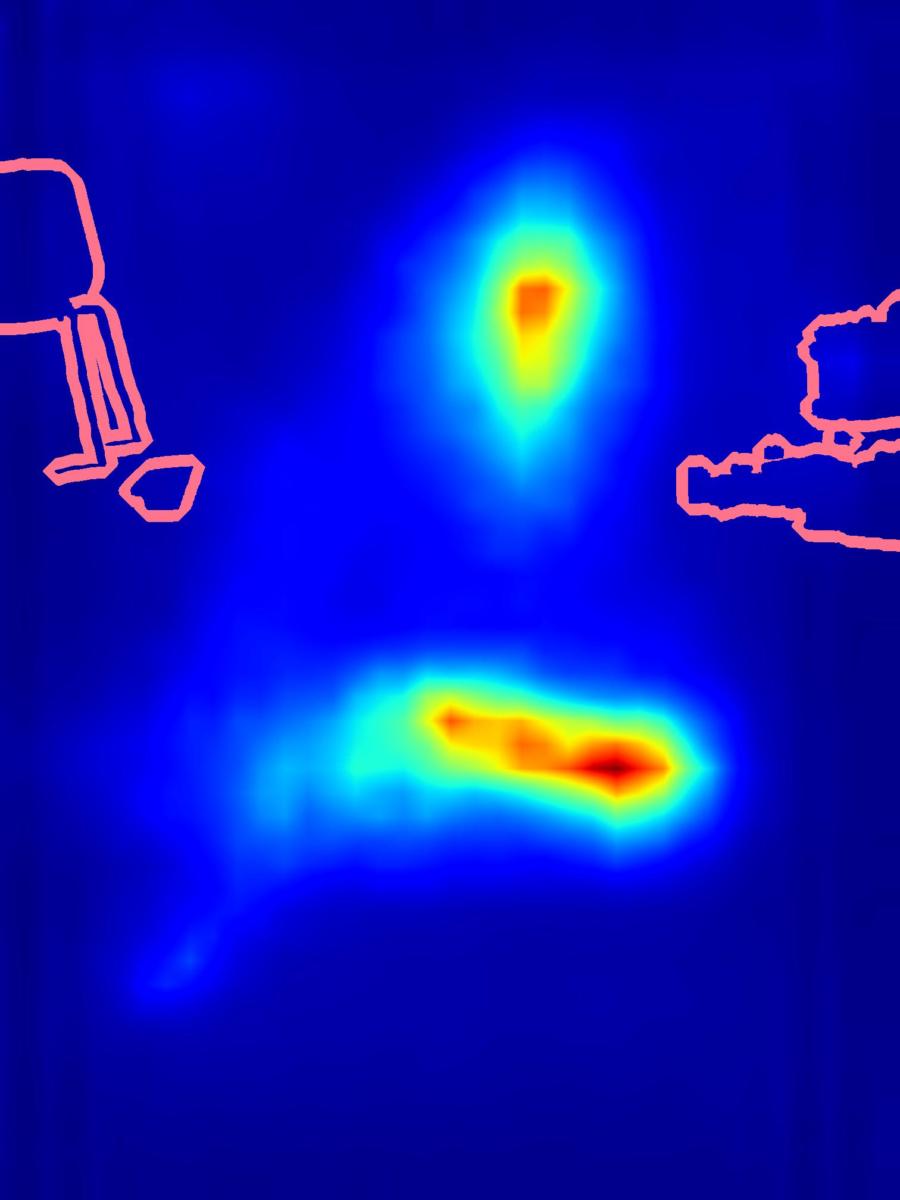 |
 |
|||||
 |
 |
 |
 |
 |
 |
|||||
 |
 |
 |
 |
 |
 |
|||||
 |
 |
 |
 |
 |
 |
|||||
 |
 |
 |
 |
 |
 |
|||||
 |
 |
 |
 |
 |
 |
|||||
 |
 |
 |
 |
 |
 |
|||||
| Input | Computed Saliency on Input | Measured eye-gaze on Input | Result | Computed Saliency on Result | Measured eye-gaze on Result |
Saliency increase:
| Input | Computed Saliency on Input | Measured eye-gaze on Input | Result | Computed Saliency on Result | Measured eye-gaze on Result | |||||
 |
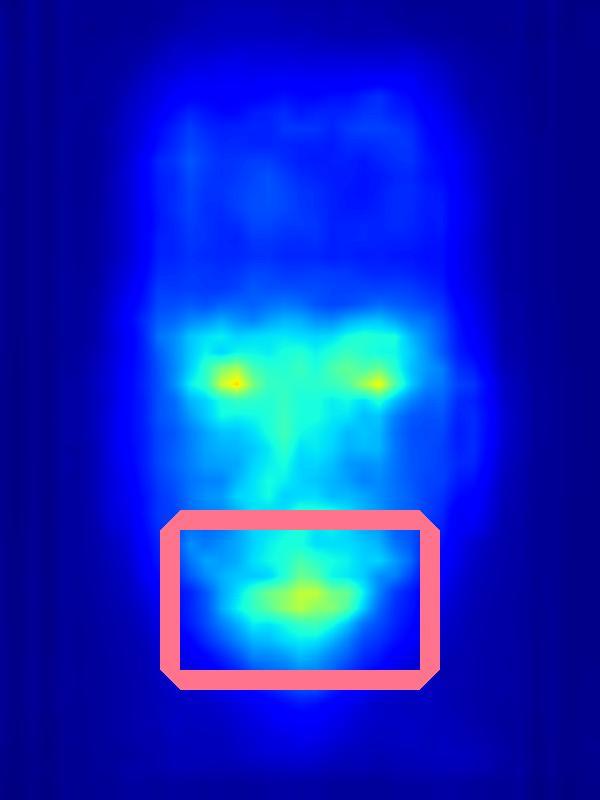 |
 |
 |
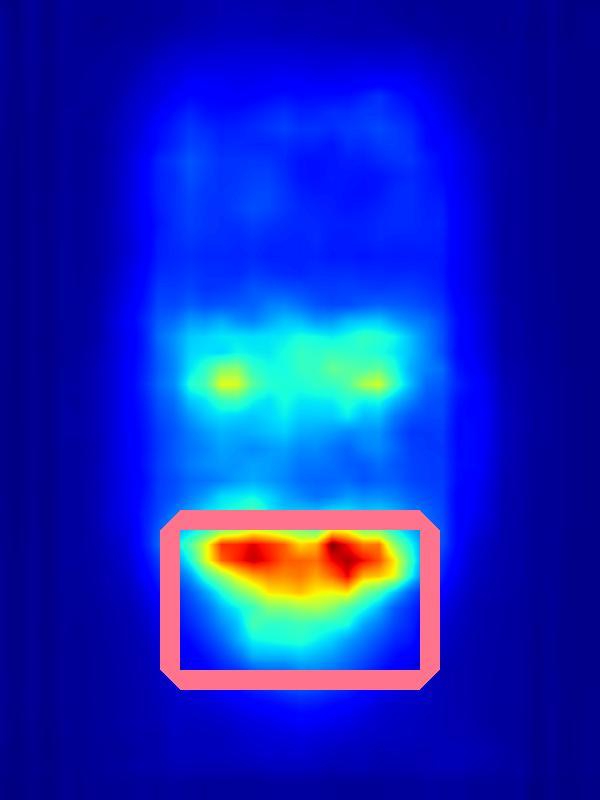 |
 |
|||||
 |
 |
 |
 |
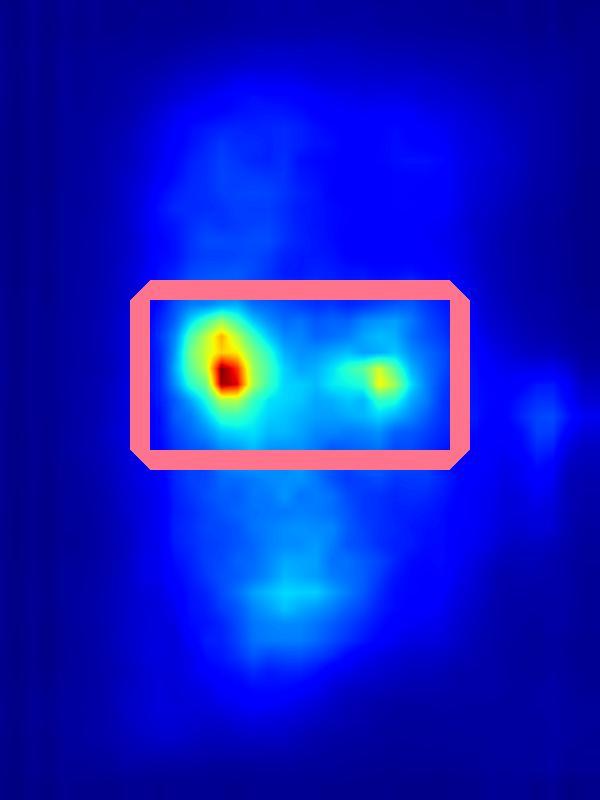 |
 |
|||||
 |
 |
 |
 |
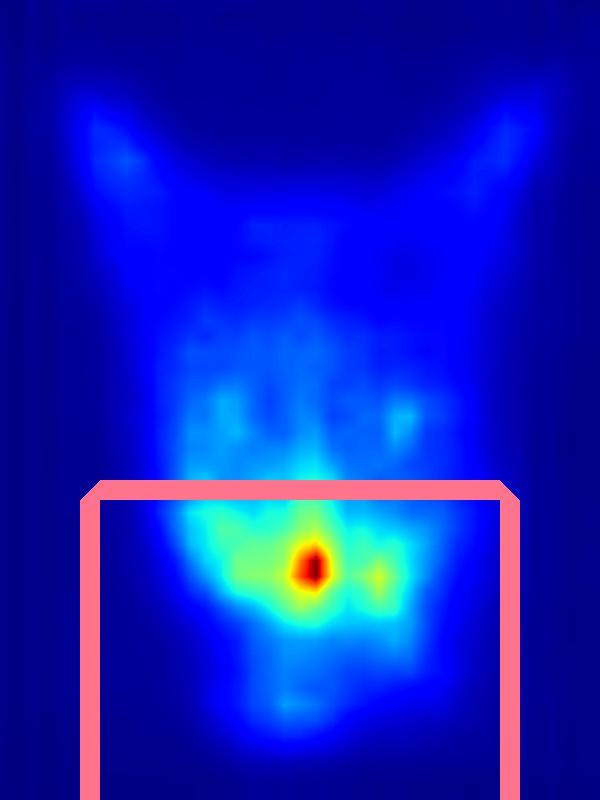 |
 |
|||||
 |
 |
 |
 |
 |
 |
|||||
| Input | Computed Saliency on Input | Measured eye-gaze on Input | Result | Computed Saliency on Result | Measured eye-gaze on Result |
5. Comparison with attention retargeting approaches
Qualitative comparison with previous attention retargeting methods on the Mechrez dataset [37], , supplementing Figure 10 in the paper:
| Input | Mask | WSR [44] | SDIM [33] | Look-Here! [34] | Ours | ||||||
 |  |  |  |  |  | ||||||
 |  |  |  |  |  | ||||||
 |  |  |  |  |  | ||||||
 |  |  |  |  |  | ||||||
 |  |  |  |  |  | ||||||
 |  |  |  |  |  | ||||||
 |  |  |  |  |  | ||||||
 |  | 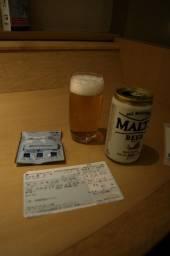 |  |  |  | ||||||
6. Comparison with "Look-Here!"
More comparisons with "Look-Here!", supplementing Figure 11 in the paper.
Comparison to recolor:
| Input | Mask | "Look-Here!" | Ours | |||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
| Input | Mask | "Look-Here!" | Ours |
Comparison to deep conv:
| Input | Mask | "Look-Here!" | Ours | |||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
| Input | Mask | "Look-Here!" | Ours |
Comparison to warp:
 |
 |
 |
 |
|||||
 |
 |
 |
 |
|||||
 |
 |
 |
 |
|||||
 |
 |
 |
 |
|||||
 |
 |
 |
 |
|||||
7. Results Driven by another Saliency Model
This is a comparison between outputs that were driven by two different saliency models (EML-Net [22] and RJY [36]), supplementing the "Results and Experiments" Section.
| Input | Mask | Saliency A [22] | Saliency B [36] | |||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
 |
 |
 |
 |
|||
| Input | Mask | Saliency A [22] | Saliency B [36] |
8. Results generated by automatically extracted masks
The input masks in these examples were generated automatically with a state-of-the-art instance segmentation tools that were guided by a course bounding box around the distracting objetcs. These results supplementing the "Discussion and Conclusions" section.
Conv:
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  | 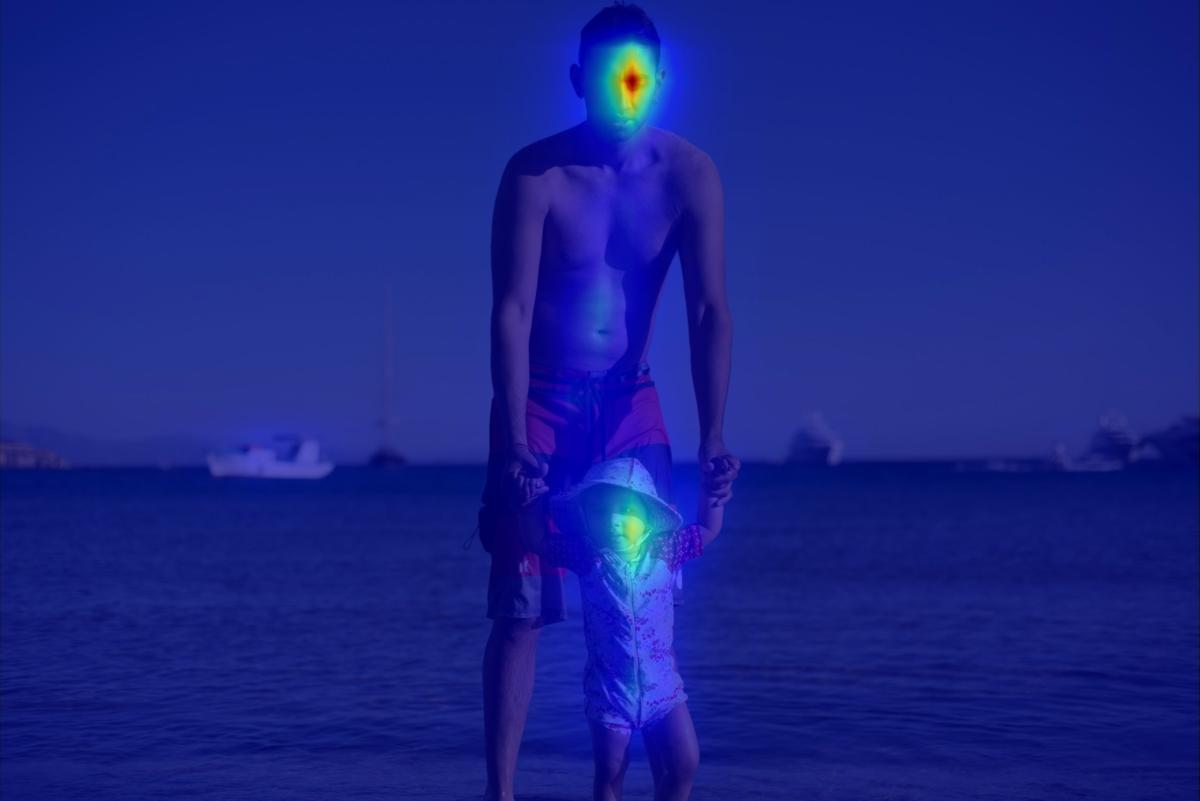 |  | 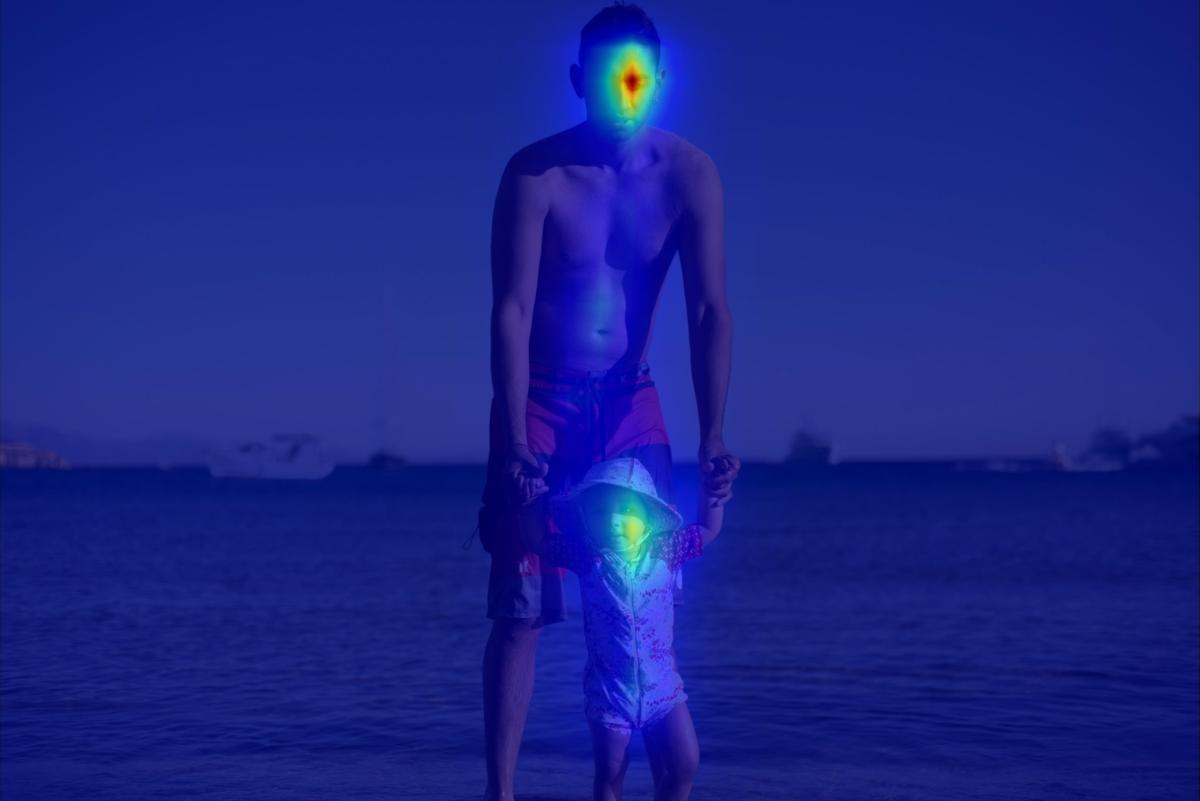 | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
Warp:
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 |  | 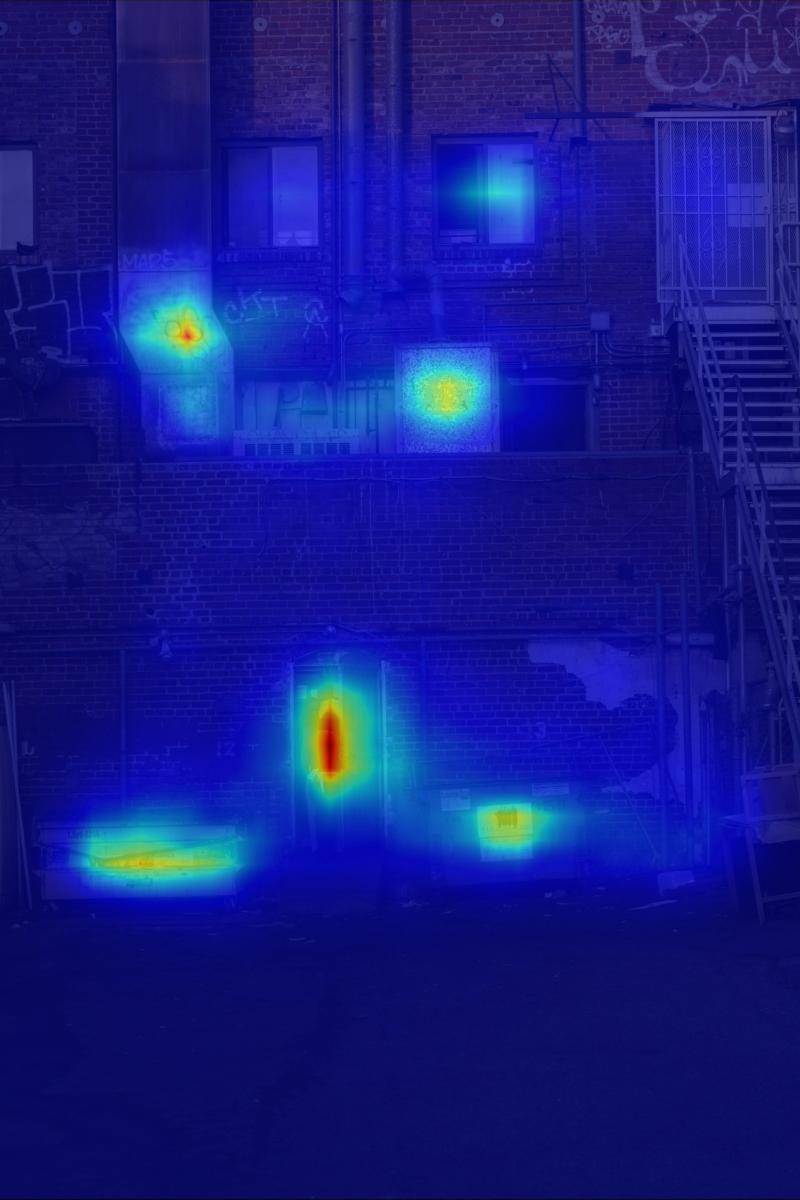 |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||
 | 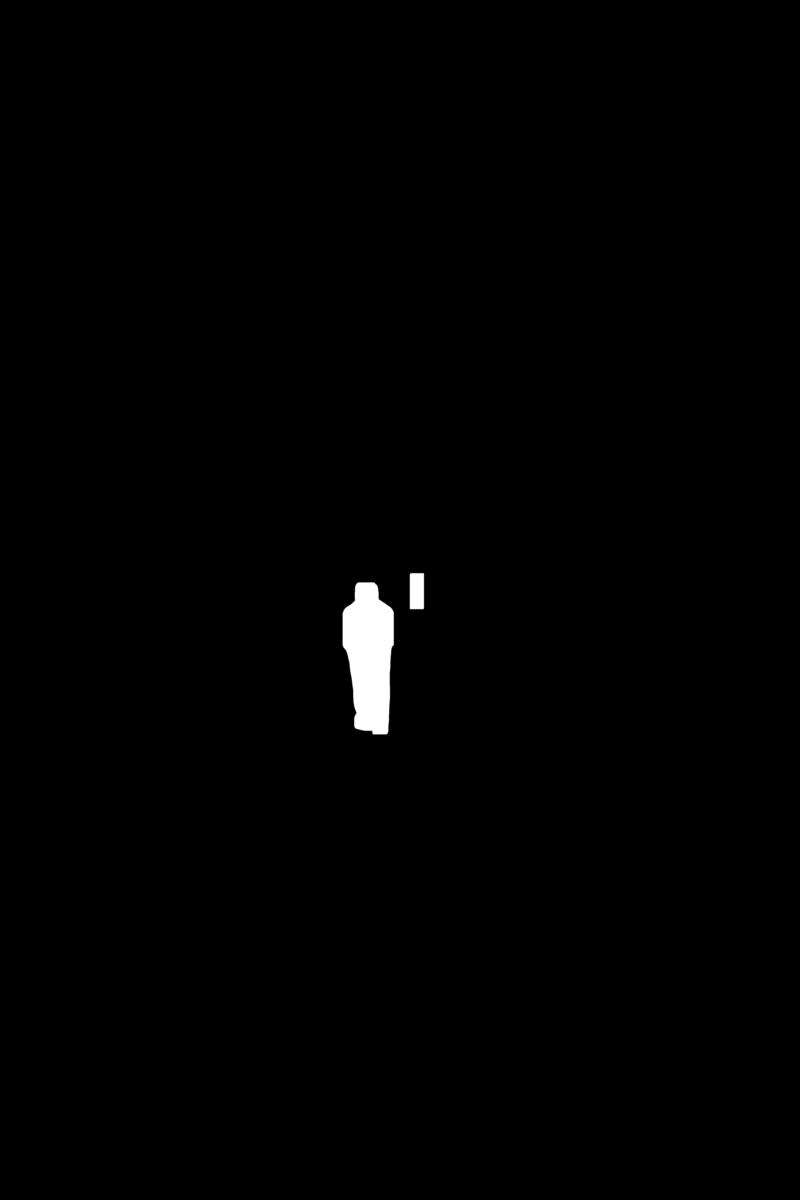 |  |  |  | |||||
 |  |  |  |  | |||||
 |  |  |  |  | |||||